
 Несколько вопросов по вопросу работы с большими данными
, MySQL (версия пока не известна, где-то в районе 5.6)
Несколько вопросов по вопросу работы с большими данными
, MySQL (версия пока не известна, где-то в районе 5.6)
|
Наши проекты:
Журнал · Discuz!ML · Wiki · DRKB · Помощь проекту |
||
| ПРАВИЛА | FAQ | Помощь | Поиск | Участники | Календарь | Избранное | RSS |
| [216.73.216.94] |

|
|
 информация о разделе
информация о разделе
 | Данный раздел предназначается исключительно для обсуждения вопросов использования языка запросов SQL. Обсуждение общих вопросов, связанных с тематикой баз данных - обсуждаем в разделе "Базы данных: общие вопросы". Убедительная просьба - соблюдать "Правила форума" и не пренебрегать "Правильным оформлением своих тем". Прежде, чем создавать тему, имеет смысл заглянуть в раздел "Базы данных: FAQ", возможно там уже есть ответ. |
Модераторы: Akina
Несколько вопросов по вопросу работы с большими данными
, MySQL (версия пока не известна, где-то в районе 5.6)
|
Сообщ.
#1
,
|
|
  |
Всем привет!
Собственно, возникли вопросы по оптимизации. Ибо делать поэлементно - не наш метод... Исходные данные: * Есть таблица в БД пусть `table`, в ней есть в записях поле biginteger `point_id` уникальное, и поле `not_found`. Остальные поля не важны. * В памяти висит список порядка из 500 000 номеров (а точнее записей, в которых есть номер). Нужно организовать две операции: 1) В таблицу `table` добавить все записи из списка в памяти, но только тех, которых еще там нет - по полю `point_id` 2) В таблице `table` изменить поле `not_found` на 1 во всех записях, которые отсутствуют в списке висящем в памяти, по полю `point_id` Смущает количество 500 000. Были бы десятки или сотни, можно было бы как-то поиграться с IN, NOT IN. Какие варианты? Может как-то со временными таблицами поиграться?  |
|
Сообщ.
#2
,
|
|
|
|
WHERE IN и WHERE NOT IN - это самый медленный вариант связывания/антисвязывания. Тут разве что умный сервер сообразитЮ что по сути перед ним тупой JOIN.
Цитата Majestio @ Какие варианты? Может как-то со временными таблицами поиграться? Зависит от СУБД. И даже от точной версии. Ну и от статистики данных. Например, первая задача в MySQL прекрасно решается вульгарным INSERT IGNORE. Вторая же лучше всего сработает через индексированную временную таблицу и, в зависимости от количества записей в основной таблице, либо LEFT JOIN WHERE IS NULL, либо WHERE NOT EXISTS. |
|
Сообщ.
#3
,
|
|
|
|
Akina, благодарю!!! Ты как всегда даешь супер ответы
 |
|
Сообщ.
#4
,
|
|
|
|
Akina, нужен еще твой совет.
Вот какая ситуация. Заказчик требует детальных логов на каждую сессию. Что вставлено, что изменено, что удалено. С "пакетными" изменениями напрямую я это не могу получить, верно? Пока на ум взбрело два подхода: Детали Таблица в БД больше чем 2 500 000 записей не планируется расширятся, заказчик мамой клянется Движок БД, уточнил - MariaDB v.10.4.25 Доступ к БД будет гарантировано монопольный Какие соображения? |
|
Сообщ.
#5
,
|
|
|
|
Цитата Majestio @ Заказчик требует детальных логов на каждую сессию. Что вставлено, что изменено, что удалено. Непонятно, на каком уровне нужно логирование. Таблиц на уровне SQL-сервера? или объектов на уровне приложения? Цитата Majestio @ С "пакетными" изменениями напрямую я это не могу получить, верно? Если речь о логировании уровня таблиц, причём логировать надо только фактические изменения - то не вижу проблемы от слова "совсем". На каждую таблицу вешаем пакет триггеров, который будет копировать в таблицу логов дату-время, пользователя и внесённые изменения. Это прекрасно работает и с пакетными изменениями - серверу для запуска триггера пофиг, откуда прилетело изменение. Исключение - операции по атрибутам внешних ключей (ON DELETE/UPDATE), они не вызывают срабатывания триггеров в каскадно изменяемых таблицах. Цитата Majestio @ Делаю "снимок" таблицы во временную по полям point_id и not_fount. Выполняю преобразования по твоему совету выше. Потом сравниваю временную таблицу и реальную и нахожу изменения для логов. Вот тебе делать нечего... есть же версионка. Temporal Tables+ |
|
Сообщ.
#6
,
|
|
|
|
Спасибо, буду разбираться. Триггеры - интересно. Возможно и временных таблиц не понадобится тогда.
|
|
Сообщ.
#7
,
|
|
|
|
Попутный вопрос: можно ли как-то ускорить DROP TABLE table_name? В таблице 388 000 записей, в записи одно поле INT (11), индекс BTREE по этому полю. Как-то я с такой ситуацией не сталкивался ... запустил запрос, он вот выполняется уже 1245 сек, когда закончится - я не знаю, конечно дождусь. Но это какая-то засада
 В сети присоветовали выполнить заранее SET foreign_key_checks = 0;, но от этого не легче. В сети присоветовали выполнить заранее SET foreign_key_checks = 0;, но от этого не легче. |
|
Сообщ.
#8
,
|
|
|
|
Цитата Majestio @ можно ли как-то ускорить DROP TABLE table_name? Формально это весьма быстрая операция. Затормозить её, тем более на 20 минут, могут разве что эффекты блокирования параллельными транзакциями, да и то вряд ли настолько долго. В любом случае процесс уже запущен - жди... если его оборвать, фиг знает что получится на выходе. Но что ничего хорошего - сто пудов. Цитата Majestio @ В сети присоветовали выполнить заранее SET foreign_key_checks = 0; Ну-ну... дать бы по башке за подобные советы. Такие вещи можно делать лишь точно зная, что ты делаешь и почему, и имея гарантии, что нигде от этого не возникнет проблем. Этот запрос отключает контроль внешних ключей, причём глобально, на всём сервере, на всех базах и таблицах. Так что поиметь себе проблем - как два пальца. Ибо при обратном включении корректность внешних ключей НЕ ПРОВЕРЯЕТСЯ. Соответственно если в таблицу попали записи, которые нарушают целостность данных, это НЕ БУДЕТ ОБНАРУЖЕНО. До тех пор, пока отсутствие связанной записи где-нибудь не аукнется ошибкой, или заведомо неверным результатом, который просто невозможно будет проигнорировать. |
|
Сообщ.
#9
,
|
|
|
|
Цитата Akina @ В любом случае процесс уже запущен - жди... если его оборвать, фиг знает что получится на выходе. Но что ничего хорошего - сто пудов. Обрывал. Таблица оставалась неизменной. Видимо какие-то внутренние транзакции откатывали по обрыву сессии. Попробовал дропнуть не из GUI-клиента, а из командной строки. И о чудо!!! 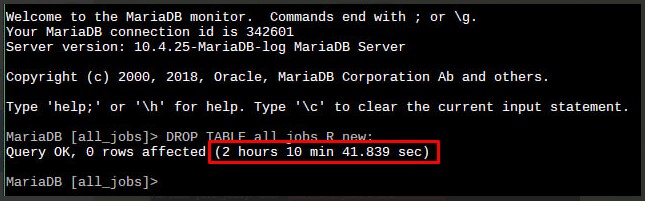 Потом заказчик написал в свою техподдержку и все исправилось  и DROP TABLR tablename и TRUNCATE TABLE tablename с таблицей с 1 600 000+ записями отрабатывают за секунду. Чудеса и DROP TABLR tablename и TRUNCATE TABLE tablename с таблицей с 1 600 000+ записями отрабатывают за секунду. Чудеса Цитата Akina @ Ну-ну... дать бы по башке за подобные советы.  |
0 пользователей читают эту тему (0 гостей и 0 скрытых пользователей)
0 пользователей:
[ Script execution time: 0.0859 ] [ 15 queries used ] [ Generated: 3.07.26, 18:28 GMT ]