
 Обратное преобразование?
Обратное преобразование?
|
Наши проекты:
Журнал · Discuz!ML · Wiki · DRKB · Помощь проекту |
||
| ПРАВИЛА | FAQ | Помощь | Поиск | Участники | Календарь | Избранное | RSS |
| [216.73.216.156] |

|
|
Обратное преобразование?
|
Сообщ.
#1
,
|
|
 |
Здравствуйте! Хотелось бы получить ответ на такой простые вопросы:
1. Существуют ли какие либо области применения результатов обратного преобразования, где это могло бы быть единственно возможным решением? 2. Может ли качество обратного преобразования каким либо параметром характеризовать качество прямого преобразования? (оба эти вопроса естественно касаются спектрального анализа речевого сигнала) |
|
Сообщ.
#2
,
|
|
|
|
Ничего не понятно. Надо вопрос разъяснить, если хочется получить ответ.
|
|
Сообщ.
#3
,
|
|
|
|
Цитата nsh @ Надо вопрос разъяснить Спасибо и за такой ответ, попытаюсь более подробно пояснить. Сразу оговорюсь что я не математик и не профессиональный программист (хотя и пишу программы на delpfi под конкретные нужды в узких рамках задачи. В нете достаточно много примеров с кодами спектрального анализа звука использующих прямое или быстрое преобразование Фурье (суть описывать не буду). Но мне нигде не встречался вариант с обратным преобразованием. Мне интересно как на слух сумма всех дискретных значений отличается от оригинала. Если быть уж совсем наглым я хотел бы чтобы кто нибудь кто занимается программированием анализа звука выложил бы здесь 2 двоичных файлика не кода, а результа кода (например форматом 20х600,8000х16, фразы типа "мама мыла раму") один до анализа, ну и второй естественно после разборки на "запчасти" и последующей сборки (можно даже с обработкой по шумам для большего качества). Так вот хотелось бы оценить современный уровень обработки сигнала.... и сравнить его с тем, что получилось у меня, потому как оценить насколько хорошо это вышло у меня не сравнивая с другим образцом я этого сделать не могу. Могу ещё добавить что для получения спектра не использовал прямое преобразование Фурье. |
|
Сообщ.
#4
,
|
|
 |
Ну вообще-то, если в прямом/обратном преобразованиях Фурье не допущено грубых ошибок, то, в теории, сигнал восстанавливается точно - матрицы прямого и обратного преобразования являются взаимно обратными. Искажения связаны главным образом с желанием получить какое-то сжатие, для чего проводится усечение коэффициентов преобразования, отбрасывается информация о фазе коэффициентов для низких и высоких частот, и т.п.
И ещё, быстрое преобразование фурье - это всего лищь быстрый алгоритм дискретного преобразования Фурье, а не какое-то отличное от него преобразование. Просто для прямого вычисления ДПФ требуется O(N2) операций, а быстрые алгоритмы обходятся O(N log N), а особо быстрые даже O(N log log N) операциями. У последних правда коэффициент великоват, так что обычно обходятся алгоритмом Кули-Тьюки. Причём даже не в общей форме (в библиотеке FFTPACK он оптимизирован для N = 2n·3m·5l), а только для степеней 2. |
|
Сообщ.
#5
,
|
|
|
|
Цитата amk @ то, в теории, сигнал восстанавливается точно Не совсем понимаю такую оценку. Это как понимать, что если в оригинальной выборке есть набор 12345, а после обратного преобразования 12346, то это теоретически точно, а 02346 неточно? Только что не зная о чём я пишу рядом сотрудник рассказал анекдот как раз в тему) Корреспондент на улице задаёт мужику вопрос: как вы оцениваете что вон из-за того угла сейчас выйдет динозавр. Мужик почесал репу: ну... приблизительно один шанс на миллион. А сейчас зададим этот вопрос женщине. Женщина не задумываясь: 50х50. КАК!?!?! Ну как, как? Или выйдет или нет! Как видите оценка даже в цифрах не всегда однозначна. Поскольку лично для меня вопросы касаются анализа речи, то мне бы было интересно не прочитать мнение, а хотя бы услышать и с чем нибудь сравнить. Хотя допускаю что это каждому человеку может подойти. Простой пример: моя жена когда слушает музыку или каких нибудь исполнителей песен совершенно не замечает фальшивых нот, которые по моему мнению совершенно нельзя не заметить, но... парадокс, поёт она совершенно идеально в отличие от меня когда моё пение сложно отличить от кота, которого тянут за хвост) Уважаемый amk если вы прекрасно разбираетесь во всех этих математических методах анализа звуков, можно ли как нибудь выложить или переслать в личку двоичную матрицу сигнала с микрофона и выходную матрицу сигнала для воспроизведения через waveoutwrite |
|
Сообщ.
#6
,
|
|
 |
Цитата olegfamus @ Не совсем понимаю такую оценку. Это как понимать, что если в оригинальной выборке есть набор 12345, а после обратного преобразования 12346, то это теоретически точно, а 02346 неточно? С точки зрения математики если мы оперируем рациональными числами, то если применить прямое, а затем обратное преобразование то результат в точности совпадёт. Что касается. Компьютера то тут числа не трансцендентные, а усечённые. Для БПФ хорошо изучен и известен порядок ошибки. Причем это младший разряд. http://www.daemonology.net/tricl/fftconv_c.pdf Цитата The maximum absolute error in a single complex element of a length-2^n convolution computed using this code is less than |x|*|y| *(14.3* n + 2.3)* eps, where |x| and |y| are the Euclidean norms of the input vectors and eps = 2^(-53). |
|
Сообщ.
#7
,
|
|
|
|
Цитата Pavia @ Что касается. Компьютера то тут числа не трансцендентные, а усечённые Меня конечно можно и убить чистой математикой), потому как я не математик, я об этом уже писал где то выше... но смысл написанного я понимаю. Вообще то в этой теме я не собирался обсуждать возможности обратного преобразования фурье и тем более решать вопросы о его допустимости применения, я обратился даже не к математикам, а специалиста, которые используют прямое преобразование (скорее всего программистам), в надежде что кто нибудь ответит на поставленные достаточно узкие вопросы), пока не более зы думал что ответы получу достаточно быстро тем более при таком количестве просмотров темы (такое впечатление что просматривали по 100 раз два-три человека)) |
|
Сообщ.
#8
,
|
|
|
|
Цитата olegfamus @ Проблема в том, что вопросы оказались такие узкие, что их просто не видно. Первый, при первом прочтении вообще выглядит бессмыслицей. Второй, в своей "узкой" форме имеет вполне для тех, кто хоть немного знаком с преобразованием Фурье и математикой вообще, имеет единственный ответ - нет.в надежде что кто нибудь ответит на поставленные достаточно узкие вопросы), пока не более Сейчас на форуме стало меньше народа, большинство не сидит тут постоянно - заходит раз в день. Ровно через сутки поступил первый ответ: "Ничего не понятно". Вопрос оказался слишком узким - понять его может только тот, кто работает над проблемной задачей - тот, кто его задал. К тому же, обработка звука не единственная область где применяется программирование, нельзя рассчитывать, что среди участников окажется кто-то занимающийся тем же, что и человек, задающий вопрос. Поэтому и приходится тщательно формулировать вопрос, чтобы и не выдать лишнего, и чтобы проблема была понятна и тем, кто работает хотя бы не слишком далеко от проблемной области. |
|
Сообщ.
#9
,
|
|
|
|
olegfamus
Цитата olegfamus @ Вообще то в этой теме я не собирался обсуждать возможности обратного преобразования фурье и тем более решать вопросы о его допустимости применения, я обратился даже не к математикам, а Тогда зачем вы в первом сообщении спрашивали про обратное преобразование?  Основная проблема то, что понять вас невозможно. Цитата olegfamus @ 1. Существуют ли какие либо области применения результатов обратного преобразования, где это могло бы быть единственно возможным решением? Нет. Путей решения может быть сколько угодно. Просто БПФ при определенных условиях может оказаться быстрее других методов. Цитата olegfamus @ 2. Может ли качество обратного преобразования каким либо параметром характеризовать качество прямого преобразования? (оба эти вопроса естественно касаются спектрального анализа речевого сигнала) Они однозначные. Так что качества параметров качества у них нету. Цитата olegfamus @ Не совсем понимаю такую оценку. Это как понимать, что если в оригинальной выборке есть набор 12345, а после обратного преобразования 12346, то это теоретически точно, а 02346 неточно? Цитата Мне интересно как на слух сумма всех дискретных значений отличается от оригинала. Никак не отличается. 3 секунды звука даже ни одного бита не изменится, ни потеряется. Вот больше будут единичные ошибки но на слух вы их не отличите. Так как слух берёт максимальные амплитуды, а ошибки у нас с минимальной амплитудой. Правда так никто не делает. Есть два пути: 1. Потоковая обработка БИХ или КИХ фильтрами или ещё каким. 2. Обработка скользящим окном. Так вот для первого известны все оценки качества. Для второго обычно эксперементальным путём. Собираете набор звуков(датасет) собирается выборка от пользователей которые обрабатывают звук вручную. А потом уже автоматические алгоритмы подгоняют под ручные результаты. Это уже обучение всяких НС. Под ручной обработкой понимается всё что угодно. Для примеру проставка оценки: нравится не нравится мелодия. Или разбиение песен по жанрам или ручное выписывание ритма(быстрый, или средний, или медленный, или 60 ударов в секунду). Конкретно звуком я не занимаюсь, но работаю в смежной области графики. Поэтому пример привести не смогу. Но ответить могу на большинство вопросов. Добавлено Цитата olegfamus @ есть набор 12345, а после обратного преобразования 12346, то это теоретически точно, а 02346 неточно? Для сравнения можно применять метрику. Это функция которая выдаст число от двух параметров. К примеру // Среднеквадратичное отклонение ошибки (англ. Mean squared error) function MSE(a,b: TArrayReal):Real; Overload; //Пиковое отношение сигнала к шуму (англ. peak signal-to-noise ratio) function PSNR(a,b: TArrayReal):Real; Overload; //dB // Квадратичное среднее sqrt(сумма(sqr(x[i]))/n) function RMS(a: TArrayReal):Real;Overload; |
|
Сообщ.
#10
,
|
|
|
|
Цитата amk @ понять его может только тот, кто работает над проблемной задачей - тот, кто его задал. Полностью согласен, но для этого принято задавать уточняющие вопросы?) Цитата amk @ Первый, при первом прочтении вообще выглядит бессмыслицей вот видите... только при первом прочтении, значит не такая уж бессмыслица? тем более что на эту бессмыслицу нашёлся ответ) Цитата amk @ с преобразованием Фурье и математикой вообще, имеет единственный ответ - нет. Можете обосновать? (задаю уточняющий вопрос), потому как слово нет уж очень похоже на аксиому, что для меня является уж очень узким ответом Цитата amk @ нельзя рассчитывать, что среди участников окажется кто-то занимающийся тем же наверно вы очень серьёзно относитесь к задаваемым мной вопросам, где возможно я пытаюсь по возможности пошутить, но упаси бог кого то высмеять или поучить, на этом форуме я скорее дилетант, или по крайней мере ученик. Очень признателен всем тем кто мне отвечает) В данном случае любой ответ это опыт, хотя с некоторыми ответами я в корне не согласен, например ответ нет, поэтому и интересно почему же всё таки нет? |
|
Сообщ.
#11
,
|
|
|
|
Цитата amk @ Никак не отличается. 3 секунды звука даже ни одного бита не изменится Ну вот! Спасибо что-то подобное и ожидал услышать. Только я привык работать в основном с числами, или в крайнем случае со своим слуховым аппаратом), хотелось бы пощупать то о чём вы сказали, очень жаль что вы не работаете с речью Цитата Pavia @ это тоже мне понятно, иэто тожеСреднеквадратичное отклонение ошибки Цитата Pavia @ - с этим не согласен, с моей точки зрения это характеризует лишь качество шумоподавления, если его применяют и тогда оно обязательно будет вносить искажения в основной сигнал матрицы, или просто уровень наличия шума в том или ином сигнале, не более. Квадратичное среднее Вообще если честно меня не столько преобразование сигнал-символы, сигнал-звуки, сигнал-слова, сигнал-предложения (не путайте с сигнал-смысл)интересуют, это в той или иной степени уже реализовано. Меня интересуют какие ещё способы этого преобразования можно использовать, и какая численная разница между этими способами... при условии например что уровень полезного сигнала становиться соизмерим с уровнем белого шума, или фона музыки. Человеку с моей точки зрения в большинстве случаев удаётся легко определить порядок звуков... тем более сказанных шёпотом. Пока выделение этих звуков я и занимаюсь, и вот когда появились более-менее приличные результаты, выяснилось что надо бы их с чем то сравнить, а сравнивать пока не с чем. остаётся одно из двух или изучит досконально например метод фурье (тем более примеров скодами предостаточно) или просто обратиться к кому нибудь кто этим занимается непосредственно. Как то так) |
|
Сообщ.
#12
,
|
|
|
|
что то не зацитировалось)правильно так:
Цитата Pavia @ //Пиковое отношение сигнала к шуму (англ. peak signal-to-noise ratio) - с этим не согласен, с моей точки зрения.... |
|
Сообщ.
#13
,
|
|
|
|
olegfamus
Можно выделять звуки ниже уровня музыки. Для этого нужно выделить основные тона речи которые чаще всего встречаются и ослаблять те что реже встречаются. Либо просто тренировать нейронную сеть на датасети с шумами. Причем НС будут работать по лучше так как они локально будут подстраиваться, в отличии от первого метода. Цитата olegfamus @ с уровнем белого шума, или фона музыки. Человеку с моей точки зрения в большинстве случаев удаётся легко определить порядок звуков... Потом отпишусь. Цитата olegfamus @ - с этим не согласен, с моей точки зрения это характеризует лишь качество шумоподавления, если его применяют и тогда оно обязательно будет вносить искажения в основной сигнал матрицы, или просто уровень наличия шума в том или ином сигнале, не более. Вообще если честно меня не столько преобразование сигнал-символы, сигнал-звуки, сигнал-слова, сигнал-предложения (не путайте с сигнал-смысл)интересуют, это в той или иной степени уже реализовано. Меня интересуют какие ещё способы этого преобразования можно использовать, и какая численная разница между этими способами... Берёте датасет речи без шумов. Затем зашумляете, накладываете музыку, снижает громкость или проще говоря заглубляете. Потом пробуте вашем алгоритмом остановить и сравниваете с оригиналом. Для первого приближения хватит MSE, оно покажет качественен лучше или хуже работает алгоритм. А так конечно лучше всего оценка людьми лучше или хуже. Но где их взять? Скорее всего нигде поэтому ставиться лучше на стандартных метриках. Добавлено Цитата olegfamus @ - с этим не согласен, с моей точки зрения.... Цитата olegfamus @ что то не зацитировалось)правильно так: Цитата Pavia @ 18 января, 22:09 //Пиковое отношение сигнала к шуму (англ. peak signal-to-noise ratio) - с этим не согласен, с моей точки зрения.... Чётких критериев по выборку метрик не существует. PSNR у меня не реализовано так как в каждой области своё понятие сигнал и шум. Просто я вам из практики скажу что пиковое значение более качественно чем просто усреднить(найти СКО). Потому что в естественных данных частенько преобладает экспоненциальное распределение данных.  |
|
Сообщ.
#14
,
|
|
|
|
Цитата Pavia @ Берёте датасет речи без шумов Считаю что уже в этом варианте кроется серьёзная ошибка. я могу сбросить входной файлик с которым мне приходится работать (реальные полевые испытания алгоритма), самое большое, что вы можете на начальном этапе выжать это уровень шумов (абсолютное значение) и спектр(относительное). Понятно, что алгоритм дальнейшей обработки должен тренироваться (в вашем понимании) и найти закономерности в моём зы как выложить файлик пока не понял практически) буду изучать правила форума) пока не получается возможно 24к слишком много) |
|
Сообщ.
#15
,
|
|
|
|
Цитата olegfamus @ пока не получается возможно 24к слишком много вроде до 100 разрешено, правда не нашёл пока про расширение Прикреплённый файл  M20x600.rar (11.62 Кбайт, скачиваний: 1090) M20x600.rar (11.62 Кбайт, скачиваний: 1090)
получилось! зы очень интересно мнение о возможности распознавания в таком варианте? |
|
Сообщ.
#16
,
|
|
|
|
olegfamus
Можете выложить алгоритм чтения в линейный массив. А то не понятно как правильно читать ваши 20х600? У вас там 2 канала или один? И частота дискретизации какая? |
|
Сообщ.
#17
,
|
|
|
|
Цитата Pavia @ Можете выложить discret = 8000; wFormatTag := WAVE_FORMAT_PCM; nChannels := 1; nSamplesPerSec := discret; wBitsPerSample := 16; nBlockAlign := nChannels * (wBitsPerSample div 8); nAvgBytesPerSec :=nBlockAlign * nSamplesPerSec; |
|
Сообщ.
#18
,
|
|
|
|
Цитата olegfamus @ Результат преобразования Фурье даёт нам спектр исходного сигнала. Мы, по нему можем определить, к примеру, что в звуке нет каких-нибудь частот, которые по идее должны быть, или соотношение энергии гармоник не соответствует ожидаемому. Означает ли это, что у нас некачественно выполнено ПФ? Нет, не означает. Звук мог быть изначально испорчен, и ПФ нам просто это показало.потому как слово нет уж очень похоже на аксиому, что для меня является уж очень узким ответом Можно применить к результату ПФ обратное преобразование и сравнить его с исходным сигналом. Если ОБА преобразования выполнены без ошибок, эти сигналы должны совпадать. На практике, из-за ошибок округления (в основном), эти сигналы будут слегка отличаться. Как правило это отличие за границами слышимости. Поэтом мы и не можем сказать что-либо о качестве ПФ только по обратному преобразованию. |
|
Сообщ.
#19
,
|
|
|
|
Цитата amk @ Как правило это отличие за границами слышимости Возможно, вот в этом я собственно и хотел убедиться лично) Выше мной выложен архив с фразой (типа оригинал), если всё действительно так как вы говорите, я не думаю что выполнить эти перечисленные действия чтобы получить результат займёт для специалиста много времени. Как говориться лучше один раз услышать, чем много раз услышать. |
|
Сообщ.
#20
,
|
|
|
|
Если кому интересно ПРО ОБРАТНОЕ ПРЕОБРАЗОВАНИЕ)
Провёл такой эксперимент: 1. Сделал в программе ширину выборки переменной величиной (от 2 до 250 при частоте дискретизации 8000) Выводы: При обратном преобразовании с различной величиной окна наилучшими в части разборчивости оказался диапазон от 20 до 40 (в общем то интуитивно я так и предполагал), скорее всего ничего нового я здесь не написал, просто ни в одном источнике я не встречал вменяемого обоснования по выбору ширины окна. Кстати при выборке и 2 значения и 250 я тоже различаю смысл сказанного (но тут скорее всего уже начинает влиять способность мозга дополнять пропущенные звуки)… моё субъективное, совершенно дилетантское мнение) 2. Убрал из обратного преобразования фазовый сдвиг, определённый при прямом преобразовании. Выводы: Наличие или отсутствие фазового сдвига при обратном преобразовании совершенно не влияет на конечный результат. Под конечным результатом я понимаю качество услышанного собранного звука. На качество влияет только количество и амплитуды частот в выборке, а не их взаимное расположение на оси времени. Мало этого наилучший результат в качестве сигнала достигается вообще при случайной (Random) начальной фазе. А ели фаза вообще не имеет никакого значения для конечной цели (распознавания звуков) то задача упрощается на порядок по производительности. |
|
Сообщ.
#21
,
|
|
|
|
Цитата olegfamus @ Ну правильно. Ухо человека не воспринимает фазу колебаний, если не во всём диапазоне частот, то в большей его части. Наличие или отсутствие фазового сдвига при обратном преобразовании совершенно не влияет на конечный результат. |
|
Сообщ.
#22
,
|
|
|
|
amk
По поводу уха не знаю. Но суть в том что DCT не содержит фазу и является обратимым. Отличие от FFT оно требует на 1 бит информации в косинусе больше, но при этом отсутствует мнимая составляющая в виде синусов. Другими словами FFT очень избыточен. |
|
Сообщ.
#23
,
|
|
|
|
Цитата Pavia @ Ничуть. При DFT вещественного сигнала отбрасывают старшую половину преобразования, поскольку преобразование симметрично. В результате, на выходе наблюдается в точности то же количество информации, что и после DCT.Другими словами FFT очень избыточен. Но при этом DFT позволяет проще производить манипуляции в частотной области, к примеру, вычислять свёртку или корреляционную функцию. Добавлено Цитата Pavia @ Есть много преобразований, не содержащих фазу, DCT только одно из них. Всё зависит от выбора базисных функций. Некоторые ещё и обходятся без умножений (преобразование Хоара). Вообще, любая вещественная ортонормированная матрица задаёт какое-то преобразование вещественной последовательности (соответственно любая комплексная - комплексной последовательности). суть в том что DCT не содержит фазу и является обратимым Какое-то время много говорили про преобразование Хартли. Но в конце концов оказалось, что оно не сильно и выигрывает у ПФ, а при вычислении свёрток и вовсе ничего не выигрывает. |
|
Сообщ.
#24
,
|
|
|
|
Цитата Pavia @ Другими словами FFT очень избыточен Если я вас правильно понял, то FFT лишь позволяет восстановить исходный сигнал с точностью до бита? для человека же этот набор не является единственным однозначным подтверждением точной копии сигнала? (потому как у той матрицы которую я выложил выше есть бесчисленное количество двойников, отличающихся порядком цифр, и совершенно не отличимых на слух). |
|
Сообщ.
#25
,
|
|
|
|
olegfamus
Если на входе FFT у нас N комплексных чисел, то на выходе N комплексных чисел(2*N действительных чисел). Если на входе FFT у нас N действительных чисел(звук), то на мы можем уменьшить число чисел в 2 раза. Если заменить FFT на DCT, то на мы можем уменьшить число чисел ещё в ~2 раза. Такое преобразование обратимо и без потери информации. Так как такое преобразование выполняется без потерь, то резонно предположить что мозгу безразлична фаза. Однако это надо проверять. Далее идут методы с потерью информации. Если частоты DCT усреднить по схеме MFCC, то на выходе мы имеем 8 чисел на 25 мс. https://www.academia.edu/2519895/Examining_...ion_Performance К сожалению данное исследование не достаточно хорошее. Для кодирования большинства гласных достаточно 2 коэффициентов из 8. |
|
Сообщ.
#26
,
|
|
|
|
Цитата Pavia @ Коргда на входе DFT действительная последовательность, то если N чётно, из N полученных комплексных чисел 2 на самом деле действительные. Остальные разбиваются на пары комплексно-сопряжённых чисел. Это и позволяет уменьшить выход наполовину. Если N нечётно, то действительное число на выходе одно, но остальные тоже делятся на пары комплексно-сопряжённых.Если на входе FFT у нас N комплексных чисел, то на выходе N комплексных чисел(2*N действительных чисел). Если на входе FFT у нас N действительных чисел(звук), то на мы можем уменьшить число чисел в 2 раза. Цитата Pavia @ А вот выход DCT такой избыточностью не обладает. поэтому и сократить ничего нельзя. Вообще в любом обратимом преобразовании так, число выходных действительных величин должно равняться числу входных. Если на выходе больше, то часть из них можно убрать и восстановить по оставшимся.Если заменить FFT на DCT, то на мы можем уменьшить число чисел ещё в ~2 раза. На самом деле DCT и DFT связаны довольно простым соотношением. Поэтому можно сделать DCT и быстренько по нему получить DFT. И наоборот. (На самом деле начало DFT продолженной последовательности в точности равно DCT) |
|
Сообщ.
#27
,
|
|
|
|
Цитата olegfamus @ На качество влияет только количество и амплитуды частот в выборке Тут я похоже маху дал) я пошёл дальше и решил проверить действительно ли разборчивость зависит от амплитуды? как оказалось амплитуду тоже можно исключить из расчётов. Если из спектра выделить определённый диапазон относящийся исключительно к полезному сигналу, а амплитуде присвоить какую нибудь const (например достаточный для прослушивания уровень громкости) - результат будет одинаков с точки зрения распознавания слов Вывод: для распознавания звуков достаточно иметь в наличии только частотные комбинации (при этом эти комбинации не должны зависеть от мужского женского или детского тембра - думаю это уже отдельная тема), что ещё более упрощает задачу с производительностью) зы: выводы я пишу скорее всего для себя, а не в качестве аксиомы для остальных исследователей. Просто мне интересна реакция профессиональных специалистов на такие утверждения. Возможно я что то упустил в своих параметрах и такие результаты получились у меня случайно) возможно математика всё объяснит, как это было с фазой? |
|
Сообщ.
#28
,
|
|
|
|
olegfamus
Амплитуда нужна для поиска локального максимума. Можно сделать локальную бинаризацию. Берём окно 25 мс удаляет постоянную составляющую, затем переводим в частоты находим среднее и используем в качестве порога: всё что выше среднего 1 всё что ниже 0. Цитата olegfamus @ математика всё объяснит, как это было с фазой? Вы неправильно понимаете суть математики. Математика работает в рамках своих аксиом. А вот какие формулы можно или нельзя использовать в качестве аксиома определяет природа вещей, естество. Для этого и нужны учёные что-бы вот в таких вот задачах находить формулы. Для примера можете построить треугольник с гепотинузой 10 см. Можете. А найти площадь при опущенной на неё высоте в 6 см. Тоже можете. Площадь равна половине произведения основания на высоту. S=1/2*c*h. Однако естество прямоугольного треугольника запрещает использовать h>5 см. Другими словами какие законы включать или выключать определяет естество. Или какими формулами можно пользоваться, а какими нельзя. Тут хорошо что естество выводится. Однако в прикладных областях включая распознавание звука это не выводится. А экспериментально обосновывается из сходя из гипотез учёных. Цитата amk @ А вот выход DCT такой избыточностью не обладает. поэтому и сократить ничего нельзя. Вообще в любом обратимом преобразовании так, число выходных действительных величин должно равняться числу входных. Если на выходе больше, то часть из них можно убрать и восстановить по оставшимся. Ваше утверждение ложное. Рассмотрит симметричные вейвлеты Добиши. |
|
Сообщ.
#29
,
|
|
|
|
Цитата Pavia @ удаляет постоянную составляющую А какой способ вы имеете в виду? хочу проверить рекомендацию |
|
Сообщ.
#30
,
|
|
|
|
olegfamus
Цитата olegfamus @ А какой способ вы имеете в виду? хочу проверить рекомендацию Есть два алгоритма. 1. Во временной области рассчитываете среднее и вычитаете из сигнала. 2. Фильтр высоких частот, т.е высокие пропускаем низкие обособляем. В статьях видел рекомендацию частотой среза в 1 КГц (как-то много). Думаю спуск(крутизна фильтра) должен быть пологим. Ищите онлайн калькулятор фильтра там списываете коэффициенты и подставляете их в КИХ (FIR) фильтр. Лично я пока играюсь с Гаусовым фильтром у меня лучший результат сглаживание по 150 отсчётов на fd=8000. На звукоформе после ФНЧ видны усиления и ослабления сигнала. Смыкания и размыкания губ? Они тоже не влияют. 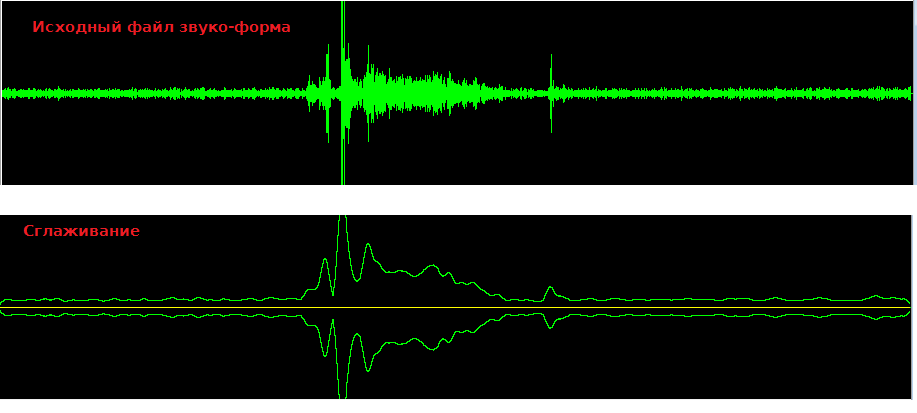 Основная цель убрать эффект растекания спектра(Имени кого не помню) который возникает из-за того что правый конец сигнала не совпадает с левым по амплитуде. Получается ступенька, а она имеет спектр вида Sinc(f) в частотной области. Короче из-за того что частота исходного сигнала не совпадает с периодом DFT получаем пик/горку вблизи 0 частот. Вот его надо убрать. Вычитание среднего отлично с этим справляется. 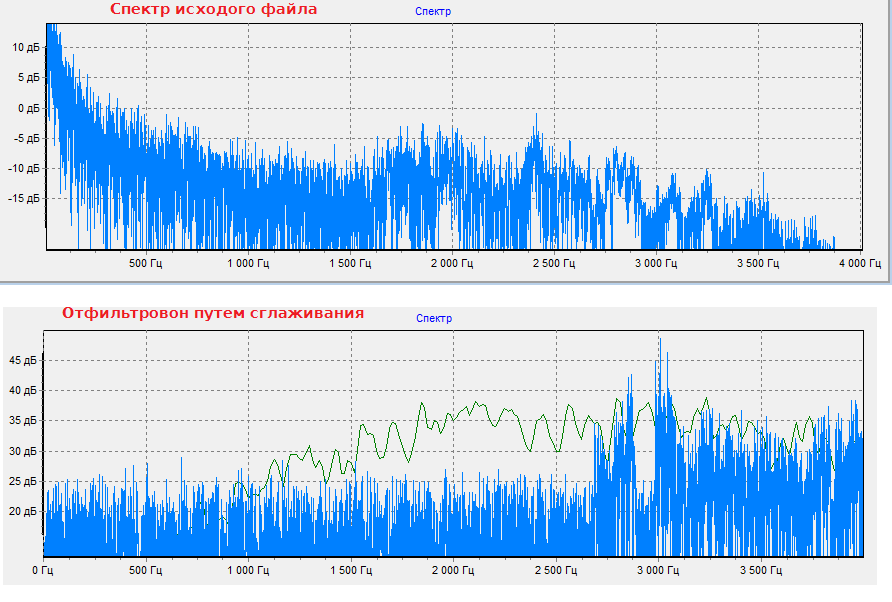 |
|
Сообщ.
#31
,
|
|
|
|
Цитата Pavia @ Лично я пока играюсь с Гаусовым фильтром лично я пока балуюсь методами Монте-Карло, ну и конечно распределением Гауса, и результаты (промежуточные) вначале были такие же. Моё отношение к ним -не тот результат, который я хотел бы получить в итоге. Вы пробовали восстановить исходный сигнал из сглаженного спектра? Совпадает он с исходным? и наконец я пытаюсь работать с сигналом, в котором и полезный сигнал то едва различим. Но раз человек его различает, то и машина его должна различать. и если этого добиться - это и будет тот результат, который мне интересен. |
|
Сообщ.
#32
,
|
|
|
|
Цитата olegfamus @ Моё отношение к ним -не тот результат, который я хотел бы получить в итоге. Вот и у меня так же. Пэтому я пока отложил потом вернусь перепроверю. Цитата olegfamus @ Вы пробовали восстановить исходный сигнал из сглаженного спектра? После вычитания это уже не обратимый процесс. Однако на слух я разницы не заметил. Хотя по идеи должна. И плюс спектры ведут себя странно. |
|
Сообщ.
#33
,
|
|
|
|
Цитата Pavia @ Можно сделать локальную бинаризацию. Берём окно 25 мс удаляет постоянную составляющую, затем переводим в частоты находим среднее и используем в качестве порога: всё что выше среднего 1 всё что ниже 0 1. попробовал этот вариант, только со своими входными данными: входной сигнал выложен выше, окно 2,5 мс, 45 дискретных частот (хотелось бы уложиться в 32, иначе придётся перестраивать всю архитектуру вычислений (шутка), может 45 это предел?), ну и несколько иной от среднего порог (подобрал по чёткости на выходе) получил собранный выходной сигнал: Прикреплённый файл 20x600_pavia.rar (9.45 Кбайт, скачиваний: 892)
2. тот же сигнал на входе, тот же алгоритм разложения по частотам и тд (символ в символ), кроме "Во временной области рассчитываете среднее и вычитаете из сигнала." вместо этого применил несколько другой способ избавиться от постоянной составляющей, но тоже из математики 5 или 6 класса (пока не буду писать какое, тайны никакой нет все его прекрасно знают, сначала нужно проанализировать, может этот эффект только с моими входными данными) второй собранный вариант (естественно и второй и первый без последующей обработки, кроме порога о котором писалось выше и который в обоих случаях одинаков) Прикреплённый файл 20x600_olegfamus.rar (6.34 Кбайт, скачиваний: 915)
что касаемо распознавания собранных сигналов, тут вы совершенно правы, если не обращать внимание на некоторые траблы, то с моей точки зрения вероятность распознавания очень высокая, несмотря на примитивность алгоритма) Добавлено Цитата olegfamus @ И плюс спектры ведут себя странно если вы о том что набор и амплитуды в этих двух спектрах совершенно не однозначные? В соседней теме Mikle писал:" строгий однополосный спектр имеет только бесконечная синусоида, если взять её кусок, то он уже имеет непрерывный спектр, чем короче кусок - тем меньше в спектре исходной частоты"-полностью согласен кроме последней фразы (вернее её несомненно будет всё меньше, но её энергия будет всегда больше остальных составляющих). С моей точки зрения если взять из бесконечного спектра с высокой долей вероятности значимую часть и сделать обратное преобразование, то с весьма высокой вероятностью на выходе мы получим ту самую синусоиду (по крайней мере на практике именно так и выходит) sorry)) понятно если в куске только 2 или 1 значение результат будет равен 0, но уже при 3 значениях (хотя решений и бесконечное множество), ответ однозначный) |
|
Сообщ.
#34
,
|
|
|
|
Цитата Pavia @ Собственно частота 0 это и есть среднее. Правда можно не обрабатывать сигнал перед DFT, а подчистить нижнее частоты уже в результате DFT. получаем пик/горку вблизи 0 частот. Вот его надо убрать. Вычитание среднего отлично с этим справляется. Добавлено Цитата Pavia @ Человеческое ухо начинает воспринимать звук только на частотах порядка 15 Гц. Всё, что ниже, воспринимается кожей как вибрация. На частоту 6-7 Гц приходится резонанс колебаний внутренних органов в теле.осле вычитания это уже не обратимый процесс. Однако на слух я разницы не заметил. Хотя по идеи должна. И плюс спектры ведут себя странно. В реальности звуки с частотами ниже 100 Гц в природе почти не возникают или имеют слишком низкую мощность. |
|
Сообщ.
#35
,
|
|
|
|
Цитата olegfamus @ В реальности звуки с частотами ниже 100 Гц в природе почти не возникают или имеют слишком низкую мощность Не совсем понял что вы имеете в виду под "в реальности", но если сделать частотный анализ выложенного мной выше сигнала 20х600, то увидите что там присутствуют частоты и 99 и значительно ниже, и даже менее 1Гц. Мало этого, на долю частот менее 100 приходиться под 80% и более мощности всего сигнала) Добавлено Правда в этих 80% нет полезного сигнала, но это уже другая тема) |
|
Сообщ.
#36
,
|
|
|
|
Неправильно выразился. У уха на нижних частотах довольно существенно падает чувствительность. Кроме того, ухо чувствительно не к мощности звука, а к звуковому давлению. Хотя давление пропорционально мощности.
Снижение чувствительности вызывается несколькими факторами, вот пара из них: Внутреннему уху не хватает размера, чтобы обеспечить нужный резонанс на низких частотах, получается, как говорят в радиотехнике, плохое согласование приёмника. На низких частотах звуковое давление достигает перепонки не только через слуховой канал, но и через носоглотку (там есть ещё один канал, ведущий на внутреннюю сторону перепонки). Из-за этого естественным звукам даже мощным, их мощности не хватает, чтобы обеспечить сравнимый со средними частотами отклик. В результате получается, что для уха названные 80% мощности превращаются в жалкие 20% (а то и меньше). В наушниках, кстати, низкие частоты слышны лучше, чем из колонок, часто даже капли-вкладыши умудряются выдать в ухо басы, несмотря на ужасное рассогласование на этот раз уже излучателей. |
|
Сообщ.
#37
,
|
|
|
|
Цитата olegfamus @ При обратном преобразовании с различной величиной окна наилучшими в части разборчивости оказался диапазон от 20 до 40 Боюсь что это слишком скоропалительные и ничем не обоснованные выводы с моей стороны, поскольку, как мне кажется, противоречат и физике и математике), скорее всего человеческий фактор накладывает свой неповторимый отпечаток), попытаюсь с этим разобраться |
|
Сообщ.
#38
,
|
|
|
|
Цитата olegfamus @ Боюсь что это слишком скоропалительные и ничем не обоснованные выводы Для тех кому интересны альтернативные речевые технологии готов поделиться своими исследованиями) Стояла задача: определиться с оптимальной шириной выборки (окна) с точки зрения цена-качество (производительность-наилучшая точность выходного сигнала, по отношению к входному)… при условии непрерывного потока и естественно непрерывного анализа на лету без потери данных. Основные входные данные: изменение ширины входного окна - от 3 значений до 100, изменение выходного окна - от 3 значений до 100 (у меня это от 0,000375с до 0,0125с). Результаты различных вариаций: 1. При слишком малых значениях входного окна: а. точность обратного преобразования наиболее высокая. Это относится исключительно к моему способу определения спектра, возможно у других соскобов преобразования будут другие результаты (требует проверки), но... б. с уменьшением окна пропадает часть данных находящихся между окнами (естественно окна без зазоров), приводить факты не буду, думаю многие поймут о чём я говорю. Решить эту проблему возможно при помощи перекрытия окон (много литературы по этому способу). Затратил какое то время на проверку и быстро успокоился - вроде есть эффект, но значительно усложняет код и производительность падает в геометрической последовательности (не мой вариант поэтому быстро забыл о нём)) в. с уменьшением окна частота окон начинает совпадать с частотами несущими основную информацию о сигнале, результат - появление в выходном сигнале огромного количества помех (а у меня их в полевых испытаниях и так выше крыши), которые значительно снижают вероятность слухового распознавания (возможно с точки зрения распознавания в коде это и не будет иметь какого либо значения, не знаю, но думаю наше идеальное устройство работает по тем же законам математики, физики, акустики и тд и следовательно если мы не сможем опознать, то и машина (моё субъективное мнение дилетанта, потому как есть достаточно много и обратных примеров)) 2. При слишком больших значениях входного окна: а. в выбору начинают попадать значения уже не 1, а 2 и более сигналов (особенно если в слове много рядом стоящих согласных), что при обратном преобразовании приводит к бубнящему сигналу (доказательства выложу позже) б. Приводит к значительному удорожанию анализа. Например при выборке в 100 значений производительность по отношению к 20 значениям падает ВДВОЕ!!!! (возможно это только при моём способе, возможно это связано с организацией структуры буферизации данных - надо проверять) 3. При слишком малых значения выходного окна а. как я ни старался подогнать код и получить хоть сколько приличный сигнал на выходе получить не удалось. Моё субъективное мнение дилетанта в анатомических возможностях человека - на таких высоких частотах наш мозг не воспринимает полезную информацию, хотя возможно я просто не верно прописал код в части вывода звука) 4. При слишком больших значениях выходного окна: такие же проблемы как и со входным окном Наиболее оптимальными результатами оказались окна (и вх и вых) в диапазоне 20-40 значений, как и писалось выше. Лично я отдаю предпочтение 20 значениям, что соответствует 0,0025с (подтверждение предположения выложу позже) |
|
Сообщ.
#39
,
|
|
|
|
Хотелось бы ещё добавить что на качество частотного анализа дополнительно влияет сам код вычисления (искажения порядка 1-2%) связанных с особенностями работы машин с вещественными числами (а в анализе почти 100% вещественные данные), результатом которых является подъём одних частот и понижением других. По цифрам или по графикам это весьма трудно определить (лично я предпочитаю работать с цифрами), но на слух различие в сигналах если в коде на одни данные ссылаются разные переменные могут хорошо прослушиваться.
С таким поведением столкнулся впервые, но после http://www.delphikingdom.com/asp/viewitem....=374&mode=print всё стало понятно) |
|
Сообщ.
#40
,
|
|
|
|
Цитата olegfamus @ Хотелось бы ещё добавить что на качество частотного анализа дополнительно влияет сам код вычисления (искажения порядка 1-2%) связанных с особенностями работы машин с вещественными числами  1-3% это эффект Гиббса, связанный с тем что для Фурье анализа нужен бесконечный сигнал, а в компьютере он у нас усечённый, т.е окно всегда имеет некоторый размер. 1-3% это эффект Гиббса, связанный с тем что для Фурье анализа нужен бесконечный сигнал, а в компьютере он у нас усечённый, т.е окно всегда имеет некоторый размер.http://www.dsplib.ru/content/filters/firwin/firwin.html А вот числах то что точность чисел тоже ограничено влияет, но не на 1-2%, а на 0,001-0,1%. |
|
Сообщ.
#41
,
|
|
|
|
Цитата Pavia @ бесконечный сигнал Если я вас правильно понял - бесконечная размерность мгновенного значения? |
|
Сообщ.
#42
,
|
|
|
|
Цитата Pavia @ а в компьютере он у нас усечённый Вообще то я писал не про это, а о том что если в коде есть частое пере присваивание одних и тех же значений разным переменным или переход с глобальных переменных к локальным возникают такие неприятные особенности как "размытый спектр" (здесь я спорить не буду, я неважный программист и всех тонкостей Delphi не знаю, возможно правильный программист изначально не допускал бы таких ошибок) что касается величины окон) как и обещал выкладываю наглядный кусочек спектра с цифрами той фразы 20х600 (кто не прослушивал, вряд ли поймёт о чём идёт речь  ) ) Прикреплённый файл  _______________________________________20__600.png (42.03 Кбайт, скачиваний: 1201) _______________________________________20__600.png (42.03 Кбайт, скачиваний: 1201)
|
|
Сообщ.
#43
,
|
|
|
|
Главное в анализе речевых данных – это выделить признаки, которые можно считать основными для идентификации лингвистического содержания. Все шумы и признаки которые отвечают за окраску можно отбросить. Принято использовать частотные или временные признаки отдельно или совместно. Считаю возможным использовать безразмерную величину как скважность, один из классификационных признаков импульсных систем, определяющий отношение периода следования (повторения) импульсов к длительности импульса.
Речевой сигнал на выходе компаратора получится прямоугольным, с импульсами с различной длительности и периодов. Смысловое содержание при прослушивании сохраняется. Чем выше частота тем ближе звук к оригиналу. В теории ни бум-бум НО проверял на практике. Речь диктора можно прокрутить быстрее или тише значит изменятся и частотные и временные характеристики. Не изменится лишь скважность. Остается найти алгоритмы нахождения участков со скважностью присущих различным комбинациям звуков. Есть, кажись, теорема что любое сообщение можно восстановить если знать каким способом оно закодировано. Читал в теории связи, поищу. Решение вопроса нужно искать у математиков, если получится задачу сформулировать кратко. Общие рассуждения не помогут. |
0 пользователей читают эту тему (0 гостей и 0 скрытых пользователей)
0 пользователей:
[ Script execution time: 0.1624 ] [ 21 queries used ] [ Generated: 2.08.26, 02:53 GMT ]