
 Сортировка по совпадающим ответам
, [MySQL]
Сортировка по совпадающим ответам
, [MySQL]
|
Наши проекты:
Журнал · Discuz!ML · Wiki · DRKB · Помощь проекту |
||
| ПРАВИЛА | FAQ | Помощь | Поиск | Участники | Календарь | Избранное | RSS |
| [18.191.228.88] |

|
|
 информация о разделе
информация о разделе
 | Данный раздел предназначается для обсуждения вопросов использования баз данных, за исключением составления запросов на SQL. Для этого выделен специальный раздел. Убедительная просьба - соблюдать "Правила форума" и не пренебрегать "Правильным оформлением своих тем". Прежде, чем создавать тему, имеет смысл заглянуть в раздел "Базы данных: FAQ", возможно там уже есть ответ. |
| Страницы: (2) 1 [2] все ( Перейти к последнему сообщению ) |
Сортировка по совпадающим ответам
, [MySQL]
|
Сообщ.
#16
,
|
|
  |
Цитата Akina @ (1-0-null, да-нет-не отвечал). А проверка на совпадение - это побитовый XOR и подсчёт соотношения количества нулевых битов к общему количеству not null битов. Основная проблема упирается в то, что таблица ответов будет сильно разреженной Таблица должна быть юзверь + правильно - не правильно (да-нет) ответил, null вообще не нужен. Цитата domencom @ matches - количество совпавших ответов. matchedQuestions - количество совпавших вопросов. Первое понятно, но что такое "количество совпавших вопросов" так и не понял  . . |
|
Сообщ.
#17
,
|
|
 |
Цитата Bas @ "количество совпавших вопросов" Это вопросы на которые отвечали совместно. Пример: ответил на вопросы: 1, 2, 5. и 1, 5, 8. Кол-во совпавших вопросов = 2 (1 и 5). Добавлено Ещё проблема в том что данные в таблицах придется постоянно перестраивать, ибо юзеры могут отвечать на вопросы дальше, либо повторно. Мне таки все ещё не понятно как можно обработать такие объемы данных за вменяемое время ... Добавлено Цитата JoeUser @ Лучше просить совет на правильных данных - большая вероятность получить правильный ответ. Ну и как тебе поможет полная формула, которая вычисляется с учетом различных погрешностей и т.д.? Задача стоит не в создании формулы... |
|
Сообщ.
#18
,
|
|
|
|
Цитата domencom @ Пример: ответил на вопросы: 1, 2, 5. и 1, 5, 8. Кол-во совпавших вопросов = 2 (1 и 5). matches тогда что? Формула тогда будет 1. Первый ответил на все правильно то 3/2*100 2. Второй ответил правильно только на один то 1/2*100.  |
|
Сообщ.
#19
,
|
|
|
|
Bas Нет понятия правильности. matches это: user1 [1 => 1, 2 => 0, 3=> 1]; user2: [1=>0, 2 => 0, 5 => 0]. matches = 1 (2 => 0). Ключ - номер вопроса, значение - ответ да/нет.
|
|
Сообщ.
#20
,
|
|
|
|
Цитата domencom @ Задача стоит не в создании формулы... Формула - есть по сути вычисляемый ключ сортировки. Твой вопрос звучит (полную картину же видишь только ты): "У меня есть большое количество данных, помогите наладить сортировку, но как - я вам не скажу"  Добавлено И еще ... уточни. Вопросы как-то группируются в "опросники", или это единый список вопросов? |
|
Сообщ.
#21
,
|
|
|
|
JoeUser, в данном случае - не известно что рассказывать для решения. Поэтому вот так вот - отвечаю на вопросы по-ходу.
Цитата JoeUser @ И еще ... уточни. Вопросы как-то группируются в "опросники", или это единый список вопросов? Единый список. |
|
Сообщ.
#22
,
|
|
|
|
Вобщем какая-то мысль витает, но не могу собрать все в "систему".
Поэтому, попробую написать типа "утверждениями" (которые не обязаны быть истинными), а вы уж попробуйте осознать, может вас "осенит" Сортировка Вообще - это способ расположения элементов по индексу (точнее, по ключу). В примитивном случае, это решается сравнением ключевого поля на "больше/меньше". В данной теме - это не совсем так, имхо. Элементы размещаются в зависимости от "расстояния", которое вычисляется по формуле. Расстояния где? Например, здесь: 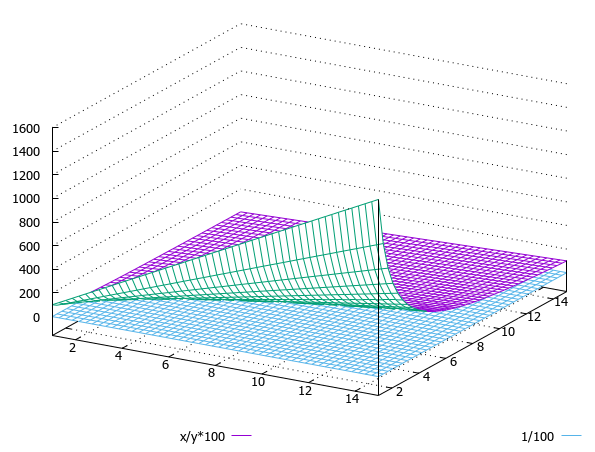 Формула z=x/(100*y) формирует ни что иное, как трехмерное скалярное поле "расстояний" ответов. Все "расстояния" ответов, в том числе и владельца - лежат на этом поле. По условию задачи, данный график можно интерпретировать и по другому - как криволинейные координаты, относительно которых считаются "расстояния" ответов прочих юзеров. Но в тензорное исчисление залезать не будем, там все бурьяном поросло, а пойдем в обратную сторону - в упрощение. Упрощаем Как видно на графике, есть еще поверхность - 1/100 (голубого цвета). Чем она хороша? Она практически инвариантна [1/(колво_совпавших_вопросов*100)] ... 1/100, пусть грубо-грубо [0..0,01]. Почему бы эту величину не взять за базис, и индексы считать не от ответов "хозяина"? Что получим? Немножко меда в ваш дёготь Предлагаемый вариант организации сортировки конечно же имеет ряд недостатков: и вычислимое поле, и неточная формула. С вычислимым полем в моем варианте наверное не избавится, даже если организовать синтетический VIEW с индексом, но в MySQL его нет, нужно делать самому. А вот с формулой можно поиграться ... А почему бы не взять не саму формулу, а ее производную, вернее сумму частных производных. Если я не забыл курс арифметики, то для f(z) = x/(100y) => f'(z) = 1/100y - x/100y2. А это уже не просто разница двух значений. Вообщем, вот как-то так |
|
Сообщ.
#23
,
|
|
|
|
Цитата Bas @ Таблица должна быть юзверь + правильно - не правильно (да-нет) ответил, null вообще не нужен. Для хранения результатов да. Для сравнения же придется вводить виртуальный вариант "не отвечал на этот вопрос". Null для этого подходит лучше любого дискретного значения. |
0 пользователей читают эту тему (0 гостей и 0 скрытых пользователей)
0 пользователей:
[ Script execution time: 0,0293 ] [ 15 queries used ] [ Generated: 27.04.24, 07:04 GMT ]