
 Оптимизация PocketSphinx для аппаратной реализации
Оптимизация PocketSphinx для аппаратной реализации
|
Наши проекты:
Журнал · Discuz!ML · Wiki · DRKB · Помощь проекту |
||
| ПРАВИЛА | FAQ | Помощь | Поиск | Участники | Календарь | Избранное | RSS |
| [216.73.216.90] |

|
|
Оптимизация PocketSphinx для аппаратной реализации
|
Сообщ.
#1
,
|
|
 |
Хотелось бы узнать, пробовал ли кто-нибудь реализовать распознавание речи с ограниченным словарем ( < 100 слов) на основе МК. Какие требования по производительности и памяти следует предъявлять к МК для реализации такой системы?
Какие можно предложить способы для минимизации размера акустической модели, а также самого исполняемого файла. Например, существует различные форматы для хранения языковой модели (.lm, .dmp, .fsg, .jsgf) одни из которых представляют данные в текстовом виде, другие в бинарном. Аналогично и с акустической моделью. А нет ли возможности, после инициализации объекта декодера, полностью сохранить его состояние в память, а затем загрузить его минуя стадию разбора командной строки и построения внутренних объектов на основе данных из текстовых файлов? Во-вторых, нельзя ли сократить размер акустической модели? Наверняка, для фраз из ограниченного набора слов, некоторая часть моделей трифонов не будет использована. Можно ли вырезать избыточные модели или вообще преобразовать модель к контекстно-независимым звуковым единицам? Если уменьшить число коэффициентов в акустической модели уже после обучения. Будет ли она работоспособна?  |
|
Сообщ.
#2
,
|
|
|
|
Тоже интересует данная тема.
Про Sphinx ничего не скажу, но Microchip когда-то делал оптимизированную голосовую библиотеку для своих контроллеров. Цитата dsPIC30F SPEECH RECOGNITION WORD LIBRARY BUILDER USER’S GUIDE и также Цитата dsPIC30F Speech Recognition Library Про ресурсы написано такое: Цитата Resource Requirements Sampling Interface: Si-3000 Audio Codec operating at 12.0 kHz System Operating Frequency: 12.288, 18.432 or 24.576 MHz Computational Power: 8 MIPs Program Flash Memory: 18 KB + 1.5 KB for each library word RAM: <3.0 KB Пробовать не пришлось т.к. процы для меня экзотические, да и библиотека сама в объектных кодах и распространяется на CD. |
|
Сообщ.
#3
,
|
|
|
|
Цитата Во-вторых, нельзя ли сократить размер акустической модели? Наверняка, для фраз из ограниченного набора слов, некоторая часть моделей трифонов не будет использована. Можно ли вырезать избыточные модели или вообще преобразовать модель к контекстно-независимым звуковым единицам? Если уменьшить число коэффициентов в акустической модели уже после обучения. Будет ли она работоспособна? Да, можно так сделать. |
|
Сообщ.
#4
,
|
|
|
|
Продолжаю вникать в PocketSphinx, пытаясь понять внутреннюю организацию библиотеки. В исходниках довольно мало комментариев, а на сайте CMU Sphinx я нашел только общее описание применяемых подходов. Более подробное описание нашел в статье, описывающей некоторые детали реализации декодера http://www.merl.com/publications/docs/TR2003-110.pdf
Есть ли еще какие-нибудь источники описывающие особенности реализации PocketSphinx? |
|
Сообщ.
#5
,
|
|
|
|
Цитата Есть ли еще какие-нибудь источники описывающие особенности реализации PocketSphinx? Наиболее подробно алгоритмы Pocketsphinx описаны в диссертации: Efficient algorithms for speech recognition http://citeseerx.ist.psu.edu/viewdoc/summa...=10.1.1.72.3560 |
|
Сообщ.
#6
,
|
|
|
|
nsh, спасибо, очень интересная работа!
|
|
Сообщ.
#7
,
|
|
|
|
У меня возник вопрос, связанный с форматами лингвистических моделей(.lm, .dmp, .fsg, .jsgf), поддерживаемых в PocketSphinx.
Приводятся ли все эти LM к некоторой единой форме, или для разных моделей используются различные алгоритмы декодирования? Если задаю LM через грамматику, которую конвертирую в fsg формат, является ли такое представление LM оптимальным? |
|
Сообщ.
#8
,
|
|
|
|
Цитата Приводятся ли все эти LM к некоторой единой форме, или для разных моделей используются различные алгоритмы декодирования? Да, приводятся. LM можно преобразовать в FSG. Вот тут можете посмотреть страница 102: http://www.lvcsr.com/static/pubs/apsipa_09...dixon_furui.pdf Цитата или для разных моделей используются различные алгоритмы декодирования? Алгоритмы разные и используют особенности моделей языка. Цитата Если задаю LM через грамматику, которую конвертирую в fsg формат, является ли такое представление LM оптимальным? Нет не является, в lm представлении можно отслеживать эффективно контекст. Например, триграммную модель можно быстро превратить в биграмную. В FSG представлении эта информация теряется. |
|
Сообщ.
#9
,
|
|
|
|
Цитата Нет не является, в lm представлении можно отслеживать эффективно контекст Хорошо, а если преобразовать грамматику или fsg в lm модель, можно ли получить от этого какую-то выгоду? Я читал, что можно на основе грамматики сгенерировать список всевозможных фраз, а затем по нему построить лингвистическую модель. Будет ли такая модель лучше fsg представления? |
|
Сообщ.
#10
,
|
|
|
|
Цитата Хорошо, а если преобразовать грамматику или fsg в lm модель, можно ли получить от этого какую-то выгоду? Можно, lm не накладывает жёстких условий, позволяет чередовать слова в любом порядке. Цитата Я читал, что можно на основе грамматики сгенерировать список всевозможных фраз, а затем по нему построить лингвистическую модель. Будет ли такая модель лучше fsg представления? Такая модель не будет эквивалентна fsg представлению, например если в грамматики слова следовали строго одно за другим, в lm появится возможность пропускать слова. Для некоторых приложений такое преобразование имеет смысл. |
|
Сообщ.
#11
,
|
|
|
|
Спасибо за объяснения. Они очень помогли
 До этого я спрашивал о возможных путях сокращения размера акустической модели и в итоге остановился на том, что для небольшого словаря можно использовать контекстно независимые модели (-allphone_cd). Это позволило сократить общий размер акустической модели с 8 Mb (сделав mdef бинарным, общий размер станет ~5Mb) до 400 kB. При этом при распознавании фраз, определенных грамматикой, существенной разницы в точности я не заметил. Однако, совсем иная картина складывается при использовании поиска ключевого слова (-kws). Похоже, что данный поиск не поддерживает контекстно-независимого режима (-allphone_cd)? Или он очень чувствителен по отношению к контекстно зависимым фонемам? В связи с этим, я планирую добавить к контекстно-независимой акустической модели, те трифоны, которые реально используются в транскрипции ключевого слова (а может быть и всех фраз грамматики, если это не приведет к существенному увеличению размера акустической модели). Собственно для этого, я хотел узнать: - Если есть фраза "раз два" то для ее транскрипции необходимы следующие трифоны:   #base lft rt p r SIL aa b aa r s i s aa SIL e <- После звука 's' идет SIL или s aa d e <- после звука 's' идет 'd' от следующего слова d SIL v b <- Перед звуком 'd' идет SIL или d s v b <- перед звуком 'd' идет 's' от предыдущего слова v d aa i aa v SIL e Правильно, или тут что-то лишнее или наоборот, чего-то не хватает? - Достаточно ли сохранить используемые трифоны для правильной работы алгоритма поиска ключевого слова? |


|
Сообщ.
#12
,
|
|
|
|
Цитата - Если есть фраза "раз два" то для ее транскрипции необходимы следующие трифоны: В целом правильно, но kws SIL по умолчанию не вставляет. Если хочется с SIL, нужно просто добавить вторую фразу в поиск: "раз <sil> два". Цитата Достаточно ли сохранить используемые трифоны для правильной работы алгоритма поиска ключевого слова? Да Цитата При этом при распознавании фраз, определенных грамматикой, существенной разницы в точности я не заметил. Точность должна быть ниже при использовании ci модели Цитата что для небольшого словаря можно использовать контекстно независимые модели (-allphone_cd). Это позволило сократить общий размер акустической модели с 8 Mb (сделав mdef бинарным, общий размер станет ~5Mb) до 400 kB. Этот ключ действует только в режиме поиска фонем Цитата Похоже, что данный поиск не поддерживает контекстно-независимого режима (-allphone_cd)? Или он очень чувствителен по отношению к контекстно зависимым фонемам? Можно использовать контекстно-независимую модель, но точность определения будет ниже и порог срабатывания нужно другой подбирать. Добавлено Цитата Это позволило сократить общий размер акустической модели с 8 Mb (сделав mdef бинарным, общий размер станет ~5Mb) до 400 kB. Размер CI модели с десятком CD сенонов должен быть меньше 100кб. Откуда 400 взялось - не очень понятно. |
|
Сообщ.
#13
,
|
|
|
|
Цитата Размер CI модели с десятком CD сенонов должен быть меньше 100кб. Откуда 400 взялось - не очень понятно. У меня выходит, что размер mean и var примерно равен 51 (фонем) x 3(кол-во сенонов на фонему) x 39 (mfcc) x 8 (гаусс) x 4 (sizeof(float)) = 186 kB Плюс остальные файлы. Вот и выходит примерно 400 kB Цитата Этот ключ действует только в режиме поиска фонем Не совсем понял, что имелось ввиду. Я думал флаг -allphone_cd yes и означает включение режима поиска фонем Цитата Можно использовать контекстно-независимую модель, но точность определения будет ниже и порог срабатывания нужно другой подбирать. Да, я как раз пробовал с фразой "голосовое управление". Очень хорошо работало с контекстно-зависимой моделью, но для контекстно-независимой, даже при очень чувствительном пороге (-kws_threshold 1e-60...1e-300) приходилось по несколько раз повторять фразу, чтобы добиться реакции. Поэтому я и решил оставить трифоны |
|
Сообщ.
#14
,
|
|
|
|
Цитата Я думал флаг -allphone_cd yes и означает включение режима поиска фонем Режим поиска фонем включается -allphone <lm>. |
|
Сообщ.
#15
,
|
|
|
|
Цитата Режим поиска фонем включается -allphone <lm>. Понятно, спасибо Так, значит декодер сам определяет есть ли в акустической модели необходимые трифоны и, если их нет, то берет соответствующие контекстно-независимые фонемы? |
|
Сообщ.
#16
,
|
|
|
|
Цитата Так, значит декодер сам определяет есть ли в акустической модели необходимые трифоны и, если их нет, то берет соответствующие контекстно-независимые фонемы? Да |
|
Сообщ.
#17
,
|
|
|
|
Я тут заметил, что в библиотеке при добавлении битового шума (dithering) применяется арифметическая операция сложения. Это приводит к тому, что в случае, если сигнал был ограничен сверху, происходит переполнение и спектр значительно разрушается. Возможно стоит использовать битовый xor для дайзеринга. Хотя врятли это сильно поможет при распознавании таких сигналов
Тут, я орал в микрофон, чтобы увидеть чем отличается спектр при разных видах дайзеринга: 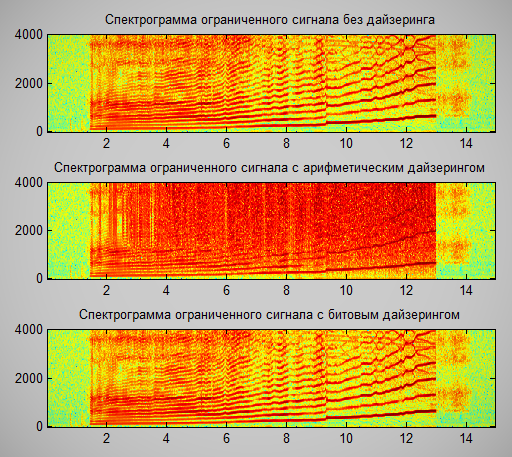 |
|
Сообщ.
#18
,
|
|
|
|
Пока не забыл)
void fe_prespch_read_pcm(prespch_buf_t * prespch_buf, int16 *samples, int32 *samples_num) { int i; int16 *cursample = samples; *samples_num = prespch_buf->npcm * prespch_buf->num_samples; for (i = 0; i < prespch_buf->npcm; i++) { memcpy(cursample, &prespch_buf->pcm_buf[prespch_buf->pcm_read_ptr * prespch_buf->num_samples], prespch_buf->num_samples * sizeof(int16)); prespch_buf->pcm_read_ptr = (prespch_buf->pcm_read_ptr + 1) % prespch_buf->num_frames_pcm; // Тут, стоит добавить // cursample += prespch_buf->num_samples; } prespch_buf->pcm_read_ptr = 0; prespch_buf->pcm_write_ptr = 0; prespch_buf->npcm = 0; return; } |
|
Сообщ.
#19
,
|
|
|
|
Цитата Я тут заметил, что в библиотеке при добавлении битового шума (dithering) применяется арифметическая операция сложения. Это приводит к тому, что в случае, если сигнал был ограничен сверху, происходит переполнение и спектр значительно разрушается. Возможно стоит использовать битовый xor для дайзеринга. Хотя врятли это сильно поможет при распознавании таких сигналов Спасибо, как-нибудь подправим Цитата Пока не забыл) Эта часть пока не закончена, в ближайшие дни доделаем. |
|
Сообщ.
#20
,
|
|
|
|
Я смотрю, в Pocketsphinx есть объект
ps_search_t *phone_loop; /**< Phone loop search for lookahead. */ но вот, не могу понять: - является ли он эквивалентом Out-Of-Grammar ветви в грамматике? <command> = Hello World | <OOG>; <OOG> = (PHONE1 | PHONE2 | ... | PHONE_END)*; - если да, то можно ли его использовать вместо того, чтобы описывать такой же phone-loop в грамматике? - Есть ли возможность управлять вероятностью входа в phone-loop и вероятностью вставки звука внутри цикла? |
|
Сообщ.
#21
,
|
|
|
|
Цитата - является ли он эквивалентом Out-Of-Grammar ветви в грамматике? Ну почти, он для других целей используется. Цитата если да, то можно ли его использовать вместо того, чтобы описывать такой же phone-loop в грамматике? Пока нельзя. Цитата - Есть ли возможность управлять вероятностью входа в phone-loop и вероятностью вставки звука внутри цикла? В jsgf можно задавать веса: <command> = Hello World | /1e-10/ <OOG>; |
|
Сообщ.
#22
,
|
|
|
|
Понятно, спасибо!
|
|
Сообщ.
#23
,
|
|
|
|
Хотелось бы понять еще одну вещь о phone-loop.
Когда декодер "заходит" в phone-loop, у него появляется множество возможных вариантов, того, какую цепочку звуков построить в соответствии с наблюдаемыми данными. Таким образом, декодер вынужден проделывать огромную работу, пытаясь установить какая из множества цепочек звуков наиболее правдоподобна, хотя мне нужно лишь знать - является ли распознанная гипотеза частью целевой грамматики или фонемного цикла. Можно ли как-то заставить декодер в phone-loop рассматривать только самую правдоподобную гипотезу, при этом не отбрасывая гипотезы, соответствующие грамматике, чтобы решить задачу определения посторонних слов, но не выполнять ненужной работы? Например, будет ли выигрыш в обработке, если phone-loop переопределить следующим образом? Ведь теперь цепочка строится из одного "слова" PHONE, имеющего 50 транскрипций jsgf <command> = Hello World | <OOG>; <OOG> = (PHONE)*; dict PHONE hh PHONE(2) f PHONE(3) gg PHONE(.) ... PHONE(50) tt ... |
|
Сообщ.
#24
,
|
|
|
|
Сейчас провел тесты с использованием 2-х вариантов задания фонемного цикла и похоже что они эквивалентны как по скорости работы так и по результату
|
|
Сообщ.
#25
,
|
|
|
|
Цитата Можно ли как-то заставить декодер в phone-loop рассматривать только самую правдоподобную гипотезу, при этом не отбрасывая гипотезы, соответствующие грамматике, чтобы решить задачу определения посторонних слов, но не выполнять ненужной работы? Эти изменения нужно вносить в код декодера. |
0 пользователей читают эту тему (0 гостей и 0 скрытых пользователей)
0 пользователей:
[ Script execution time: 0.1174 ] [ 15 queries used ] [ Generated: 27.06.26, 02:10 GMT ]