
 Оптимизация PocketSphinx для аппаратной реализации
Оптимизация PocketSphinx для аппаратной реализации
|
Наши проекты:
Журнал · Discuz!ML · Wiki · DRKB · Помощь проекту |
||
| ПРАВИЛА | FAQ | Помощь | Поиск | Участники | Календарь | Избранное | RSS |
| [216.73.216.76] |

|
|
| Страницы: (2) 1 [2] все ( Перейти к последнему сообщению ) |
Оптимизация PocketSphinx для аппаратной реализации
|
Сообщ.
#16
,
|
|
 |
Цитата Так, значит декодер сам определяет есть ли в акустической модели необходимые трифоны и, если их нет, то берет соответствующие контекстно-независимые фонемы? Да |
|
Сообщ.
#17
,
|
|
|
|
Я тут заметил, что в библиотеке при добавлении битового шума (dithering) применяется арифметическая операция сложения. Это приводит к тому, что в случае, если сигнал был ограничен сверху, происходит переполнение и спектр значительно разрушается. Возможно стоит использовать битовый xor для дайзеринга. Хотя врятли это сильно поможет при распознавании таких сигналов
Тут, я орал в микрофон, чтобы увидеть чем отличается спектр при разных видах дайзеринга: 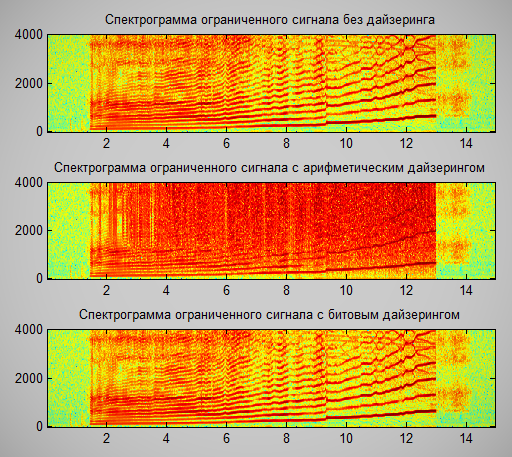 |
|
Сообщ.
#18
,
|
|
|
|
Пока не забыл)
  void fe_prespch_read_pcm(prespch_buf_t * prespch_buf, int16 *samples, int32 *samples_num) { int i; int16 *cursample = samples; *samples_num = prespch_buf->npcm * prespch_buf->num_samples; for (i = 0; i < prespch_buf->npcm; i++) { memcpy(cursample, &prespch_buf->pcm_buf[prespch_buf->pcm_read_ptr * prespch_buf->num_samples], prespch_buf->num_samples * sizeof(int16)); prespch_buf->pcm_read_ptr = (prespch_buf->pcm_read_ptr + 1) % prespch_buf->num_frames_pcm; // Тут, стоит добавить // cursample += prespch_buf->num_samples; } prespch_buf->pcm_read_ptr = 0; prespch_buf->pcm_write_ptr = 0; prespch_buf->npcm = 0; return; } |


|
Сообщ.
#19
,
|
|
|
|
Цитата Я тут заметил, что в библиотеке при добавлении битового шума (dithering) применяется арифметическая операция сложения. Это приводит к тому, что в случае, если сигнал был ограничен сверху, происходит переполнение и спектр значительно разрушается. Возможно стоит использовать битовый xor для дайзеринга. Хотя врятли это сильно поможет при распознавании таких сигналов Спасибо, как-нибудь подправим Цитата Пока не забыл) Эта часть пока не закончена, в ближайшие дни доделаем. |
|
Сообщ.
#20
,
|
|
|
|
Я смотрю, в Pocketsphinx есть объект
ps_search_t *phone_loop; /**< Phone loop search for lookahead. */ но вот, не могу понять: - является ли он эквивалентом Out-Of-Grammar ветви в грамматике? <command> = Hello World | <OOG>; <OOG> = (PHONE1 | PHONE2 | ... | PHONE_END)*; - если да, то можно ли его использовать вместо того, чтобы описывать такой же phone-loop в грамматике? - Есть ли возможность управлять вероятностью входа в phone-loop и вероятностью вставки звука внутри цикла? |
|
Сообщ.
#21
,
|
|
|
|
Цитата - является ли он эквивалентом Out-Of-Grammar ветви в грамматике? Ну почти, он для других целей используется. Цитата если да, то можно ли его использовать вместо того, чтобы описывать такой же phone-loop в грамматике? Пока нельзя. Цитата - Есть ли возможность управлять вероятностью входа в phone-loop и вероятностью вставки звука внутри цикла? В jsgf можно задавать веса: <command> = Hello World | /1e-10/ <OOG>; |
|
Сообщ.
#22
,
|
|
|
|
Понятно, спасибо!
|
|
Сообщ.
#23
,
|
|
|
|
Хотелось бы понять еще одну вещь о phone-loop.
Когда декодер "заходит" в phone-loop, у него появляется множество возможных вариантов, того, какую цепочку звуков построить в соответствии с наблюдаемыми данными. Таким образом, декодер вынужден проделывать огромную работу, пытаясь установить какая из множества цепочек звуков наиболее правдоподобна, хотя мне нужно лишь знать - является ли распознанная гипотеза частью целевой грамматики или фонемного цикла. Можно ли как-то заставить декодер в phone-loop рассматривать только самую правдоподобную гипотезу, при этом не отбрасывая гипотезы, соответствующие грамматике, чтобы решить задачу определения посторонних слов, но не выполнять ненужной работы? Например, будет ли выигрыш в обработке, если phone-loop переопределить следующим образом? Ведь теперь цепочка строится из одного "слова" PHONE, имеющего 50 транскрипций jsgf <command> = Hello World | <OOG>; <OOG> = (PHONE)*; dict PHONE hh PHONE(2) f PHONE(3) gg PHONE(.) ... PHONE(50) tt ... |
|
Сообщ.
#24
,
|
|
|
|
Сейчас провел тесты с использованием 2-х вариантов задания фонемного цикла и похоже что они эквивалентны как по скорости работы так и по результату
|
|
Сообщ.
#25
,
|
|
|
|
Цитата Можно ли как-то заставить декодер в phone-loop рассматривать только самую правдоподобную гипотезу, при этом не отбрасывая гипотезы, соответствующие грамматике, чтобы решить задачу определения посторонних слов, но не выполнять ненужной работы? Эти изменения нужно вносить в код декодера. |
1 пользователей читают эту тему (1 гостей и 0 скрытых пользователей)
0 пользователей:
[ Script execution time: 0,0323 ] [ 14 queries used ] [ Generated: 10.07.25, 13:54 GMT ]