
 Алгоритм распознавания речи
, выбор алгоритма
Алгоритм распознавания речи
, выбор алгоритма
|
Наши проекты:
Журнал · Discuz!ML · Wiki · DRKB · Помощь проекту |
||
| ПРАВИЛА | FAQ | Помощь | Поиск | Участники | Календарь | Избранное | RSS |
| [3.146.105.194] |
 Дорогие друзья! Поздравляем вас с днём Победы!
Дорогие друзья! Поздравляем вас с днём Победы!

|
|
| Страницы: (7) 1 [2] 3 4 ... 6 7 все ( Перейти к последнему сообщению ) |
Алгоритм распознавания речи
, выбор алгоритма
|
Сообщ.
#16
,
|
|
 |
Вы хорошо рассказали об диф. уравнениях. Но дальше все непонятно.
Цитата shur_nn @ В своем алгоритме для распознавания речевой комманды я использовал явление синхронизации системы. Что за система? Что такое явление синхронизации системы? Что Вы подразумеваете под амплитудой сигнала? Мгновенную амплитуду? Значение сигнала в каждом семпле? А что такое частота сигнала? Голосовой сигнал имеет целый спектр разных частот. Что за частоту Вы берёте, как ее получаете из сигнала? Цитата shur_nn @ Построив отображение реального звука (слова) я получил модель, которая циклически воспроизводит данный процесс Вы проводите какие-то математические действия на сигалом слова. В чём их суть, смысл? В результате какого-то преобразования сигнала получаете какой то его образ, модель. Откуда у Вас уверенность, что эта модель моделирует существенные стороны звуков слова? Если бы Вы построили свою модель на основании многих реализаций этого слова разными голосами, то у Вас ногла бы быть надежда, что Ваше хитрое преобразование может выделить общее, существенное и отбросить частное. Ну это как я понимаю сравниваете данный образей звука с эталоном, с моделью. Цитата shur_nn @ Основное преимущество данного подхода в том, что явление синхронизации обладает свойствами обобщения и позволяет выделять схожесть модели с входным сигналом по признакам функциональной схожести, а не конкретной реализации. Что же это за явление такое таинственное, которое обладает таким замечательным свойством, и о котором Вы совершенно ничего не рассказали? |
|
Сообщ.
#17
,
|
|
|
|
Проблема в терминологии.
Система - некий объект, который мы исследуем. Например речевой тракт человека. То-же можно сказать и о мат. модели. Процесс - последовательность смены состояний системы, которые мы фиксируем в виде временного ряда измеряемых величин. Отображение - фактически диф. уравнение системы (мат. модель) с той лишь разницей, что в диф. уравнении функция dx/dt - имеет бесконечное разрешение т.к. dt->0, а в модельном отображении мы имеем дело с дискретным временем. Соответствено обыкновенное диф. уравнение преобразуется к виду X(i)=F(X(i-1)). F - некий оператор эволюции системы. Собственно F и есть модель, которую необходимо получить по измеряемой временной последовательности. Еще раз говорю Вам, что данный вопрос довольно сложен и для его понимания Вам необходимо изучить соответствующую литературу. По поводу таинственной синхронизации, поищите в интернете темы - стахостическая синхронизация, аттрактор системы, бассейн притяжения. В этом форуме есть созданная мной тема - синтез речи при помощи звукового редактора. Собственно это есть указание на то, какие основные параметры я использовал для построения модели. |
|
Сообщ.
#18
,
|
|
|
|
Есть еще вопрос. Каким образом можно улучшить распознавание, если программа дикторозависимая, т.е. создается под конкретного человека? Может можно что-то сделать еще на этапе обработки сигнала или при получении например коэффициентов MFCC?
|
|
Сообщ.
#19
,
|
|
|
|
Цитата rommag @ Каким образом можно улучшить распознавание, если программа дикторозависимая Скорее, наоборот - если программа дикторонезависимая, то можно что-то сделать с помощью нормализации и адаптации. Специальные приёмы для дикторозависимых систем трудно представить. |
|
Сообщ.
#20
,
|
|
|
|
Итак, что изменилось за это время? Как успехи?
Почему же человек легко узнает слова, произнесенные другими людьми, искаженные, с фоном. А компьютер неспособен на это? Чуть быстрее, чуть медленнее, под музыку - все ступор. shur_nn! Давай литературу, пожалуйста!  Мне же кажется, проблема еще вот в чем. Давайте вспомним анатомию слухового анализатора. У млекопитающих орган слуха (внутреннее ухо) представляет собой полость в форме улитки. Внутри полости, спирально "натянуты" волоски рецепторов, причем разной длинны, каждый из этих волосков чувствителен к определенной частоте в диапазоне от 20 до 20 тыс Гц. (разумеется, вы знаете, что наибольшую чувствительность человек имеет в "речевом" диапазоне 1200 - 6800 Гц). Каждый волосок сязан с биполярным нейроном, который (вероятно) решает, какой силы сигнал пропустить, какой "отбраковать". Из аксонов биполярных нейронов состоит слуховой нерв. Т.е. по нему постоянно передается информация о частотном составе. Далее эти аксоны идут к кохлеарным ядрам продолговатого мозга, где их ждет переключение второй нейрон (не знаю, что он конкретно делает с сигналом), затем акстоны от второго нейрона идут к третьему (к медиальному добавочному оливному ядру и трапецевидному телу), причем 70% волокон переходят от второго нейрона на противоположную сторону, 30% остается на той же стороне. Отходя от третьего нейрона, волокна оканчивается в нижних холмиках крыши среднего мозга и в медиальном коленчатом теле (4 нейрон). Длительный путь оканчивается в 5 нейроне слуховой коры (Зона Гешле) Так вот, в этой хитрой схеме нет ни одной лишней детали (иначе эволюция давно бы их отбросила). Каждый переход от рецептора улитки до 5 нейрона связан с каким-то фундаментальным преобразованием информации с каким? я знаю только первый этап. Всего их не меньше пяти и все они функционируют единовременно, по мере поступления сигнала, без видимых "фреймов" 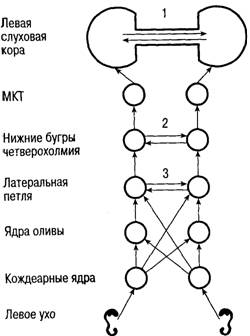 Слуховая система имеет не только много уровней, но и большое число перекрестных комиссур, благодаря которым каждое ухо проецируется в оба полушария мозга: 1 — мозолистое тело; 2 — комиссура нижних бугров четверохолмия; 3 — комиссура Пробста Есть еще вариант, что от всех(или почти) биполярных клеток "запитывается" каждая нейронная колонка в слуховой коре. Каждая колонка узнает свой образ. Но это не точно. |
|
Сообщ.
#21
,
|
|
|
|
Основые алгоритмы, которые нужно рассмореть для пословного распознавания:
1. Метод динамического программирования 2. Нейронные сети 3. Марковские модели. Но перед применением этих алгоритмов необходимо провести первичную обработку речевого сигнала 1. Ввод речевого сигнала 2. Нормализация 3. Преобразование Фурье примеры алгоритмов на Delphi есть на сайте http://signals.freezoka.com Дальше, если нужно, проводится сегментация и непосредственно распознавание. Самый простой алгоритм для реализации это метод динамического программирования. |
|
Сообщ.
#22
,
|
|
|
|
Цитата digitizer @ Основые алгоритмы, которые нужно рассмореть для пословного распознавания: Дальше, если нужно, проводится сегментация и непосредственно распознавание. Самый простой алгоритм для реализации это метод динамического программирования. Интересует по-фонемное распознавание, слова - прерогатива корковых структур. Да и нужна ли сегментация? Живой анализатор разве сегментирует? Специализированные цепочки выделяют из потока сигнала каждый свою фонему, передают возбуждение выше, на колонки, а те суммируют их и передают в кору образ. Происходит это непрерывно 24 часа в сутки. Вопрос, как это реализовано? Может кто нибудь предоставить специализированную программу распознающую фонему "А" или "Ш" независимо от диктора, громкости, скорости и окружения? |
|
Сообщ.
#23
,
|
|
|
|
Анатоль
Не мог бы ты предоставить сорцы своей программы распознавания? Я начал интерисоваться темой распознавания речи. Хотел бы поглядеть как устроена твоя программа, чтобы начать писать свою. |
|
Сообщ.
#24
,
|
|
|
|
Цитата Ungedonist @ Не мог бы ты предоставить сорцы своей программы распознавания? А что такое "сорцы"? |
|
Сообщ.
#25
,
|
|
|
|
Цитата Анатоль @ А что такое "сорцы"? Исходные тексты программ  |
|
Сообщ.
#26
,
|
|
|
|
Ungedonist
А что Вас интересует, весь исходник, или какой-то момент? |
|
Сообщ.
#27
,
|
|
|
|
Цитата Анатоль @ Ungedonist А что Вас интересует, весь исходник, или какой-то момент? меня интерисует как из непрерывного потока выбираются слова и распознаются они ведь всегда разные по длительности |
|
Сообщ.
#28
,
|
|
|
|
Цитата Ungedonist @ как из непрерывного потока выбираются слова и распознаются они ведь всегда разные по длительности Я это пробую делать с помощью предварительной (автоматической) сегментации (на слоги, фонемы). Когда известны границы (или средины) фонем, то разная их длительность не является проблемой. |
|
Сообщ.
#29
,
|
|
|
|
Цитата Ungedonist @ меня интерисует как из непрерывного потока выбираются слова и распознаются они ведь всегда разные по длительности Динамическое программирование (оно же Витерби) используется для одновременного декодирования и точного нахождения акустических состояний во времени |
|
Сообщ.
#30
,
|
|
|
|
Цитата Анатоль @ Я это пробую делать с помощью предварительной (автоматической) сегментации (на слоги, фонемы). Когда известны границы (или средины) фонем, то разная их длительность не является проблемой. Согласен, можно разделить на сегменты! Но для каждого отдельного случая длительность ыонемы своя. Как действовать в этом случае? Пусть программа распознаёт несколько слов, тогда она должна узнавать их именно по последовательности фонем? То есть надо для каждого слова хранить ещё и последовательность фонем в слове? |
1 пользователей читают эту тему (1 гостей и 0 скрытых пользователей)
0 пользователей:
[ Script execution time: 0,0483 ] [ 14 queries used ] [ Generated: 11.05.24, 12:29 GMT ]