

 Каркас таблицы (псевдографика) выводится вопросами в консоли
, чистый СИ, visual studio 2010
Каркас таблицы (псевдографика) выводится вопросами в консоли
, чистый СИ, visual studio 2010
|
Наши проекты:
Журнал · Discuz!ML · Wiki · DRKB · Помощь проекту |
||
| ПРАВИЛА | FAQ | Помощь | Поиск | Участники | Календарь | Избранное | RSS |
| [18.191.195.110] |

|
|
Полезные ссылки:
| Страницы: (2) [1] 2 все ( Перейти к последнему сообщению ) |
Каркас таблицы (псевдографика) выводится вопросами в консоли
, чистый СИ, visual studio 2010
 Сообщ.
#1
,
Сообщ.
#1
,
|
|
  |
Всем хай! Сходу к делу!
Есть код:   //SetConsoleOutputCP(866); //SetConsoleCP(866); printf(" ╔═════╦════════════════════╦════════════════════╗\n");// ╚╔ ╩ ╦ ╠ ═ ╬ ╣ ║ ╗ ╝ printf(" ║ №: ║ Марка ║ ФИО ║\n"); printf(" ╠═════╬════════════════════╬════════════════════╣\n"); при выводе вся псевдографика меняется на знаки ВОПРОСОВ (выглядит чертовски коряво). я вроде понимаю, что дело в кодировке, но как не пытался играться с setlocale, SetConsoleCP и пр. никак не могу добиться распечатки правильного каркаса... подскажите, как быть-то? |


|
Сообщ.
#2
,
|
|
 |
ИМХО дело в кодировке исходного текста. В 1251 символов псевдографики нет вообще, так что строковые литералы будут содержать что угодно, но не их. Смени кодирование на 866, вывод в консоль даже не придётся настраивать.
|
|
Сообщ.
#3
,
|
|
|
|
Цитата Qraizer @ ИМХО дело в кодировке исходного текста. В 1251 символов псевдографики нет вообще, так что строковые литералы будут содержать что угодно, но не их. Смени кодирование на 866, вывод в консоль даже не придётся настраивать. Qraizer, а ведь ты правильную идею говоришь, т к я помню, что когда начал в коде пропечатывать эти АЛЬТ-символы (через малую правую клавиатуру), а потом нажал компиляция, то VS выдала какое-то сообщение о том, что мол кодировка страницы будет сменена на что-то там. Я не придал этому значения, даже сообщение до конца не дочитал. и вот сейчас получил проблемы... Цитата Qraizer @ Смени кодирование на 866 программно или через опции VS?? P.S. я совсем запутался с этой псевдографикой в консоли VS. Вроде несложно все это, но нужно понимать нюансы очень хорошо |
|
Сообщ.
#4
,
|
|
|
|
Цитата FasterHarder @ В .c-файле. В Far-е это примерно так:программно или через опции VS?? Прикреплённая картинка
|
|
Сообщ.
#5
,
|
|
|
|
Уходите вы от этих однобайтовых кодировок!
Юникод прекрасно сохраняет псевдографику. Писать нужно в Юникоде, а выводить уже как тянет кодировка консоли. 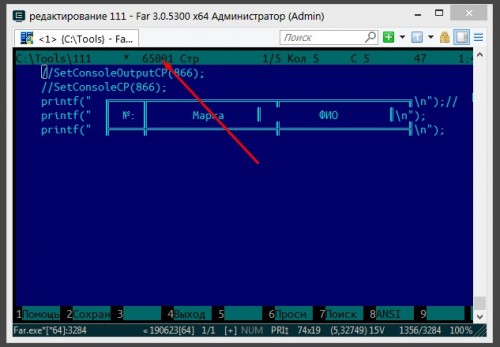 |
|
Сообщ.
#6
,
|
|
|
|
пишу код в среде Visual Studio. Там есть Файл - Дополнительные параметры сохранения
Прикреплённая картинка
по умолчанию стояла, которая выделена синим цветом. перебровал разные варианты кодировок из списка. Либо не помогает, либо вообще не дает задать выбранную кодировку. Какую из списка кодировку нужно поставить + всякие setlocale никак не мешают здесь? |
|
Сообщ.
#7
,
|
|
|
|
FasterHarder, надо отделить пчел от меда
 Однобайтовые кодировки уже давно - анахронизм. Это аксиома, если желаешь чтобы твои проги были user frendly. Многобайтовых кодировок множество, основное распространение получила UTF-8, т.к. в общем зачете для разработки программ в ней больше плюсов, чем минусов по сравнению, к примеру с UTF-16 или UTF-32. Поэтому пользуем строго UTF-8. При сохранении документов в кодировке UTF-8 нередко используют спецификацию BOM (сокращенно от Byte Order Mark). Использование UTF-8 с BOM - затея ошибочная, по сути, и Мелкософт тут лоханулся. Ибо проблемы порядка байтов для UTF-8 не существует! BOM актуален для UTF-16 и UTF-32. Более того, спецификация Unicode 5.0 настоятельно рекомендует не использовать BOM с UTF-8 (см.2.6 спецификации): Цитата ... Use of a BOM is neither required nor recommended for UTF-8, but may be encountered in contexts where UTF-8 data is converted from other encoding forms that use a BOM or where the BOM is used as a UTF-8 signature. ... А теперь про использование ... Тут два этапа - разработки и исполнения. Этап разработки В редакторе используем UTF-8 и пользуемся всеми плюшками обширной таблицы кодов. Компиляторы этому не противятся и работают прекрасно. Естественно, все строковые константы имеют многобайтную кодировку. Этап исполнения Вот тут нужно быть аккуратнее. При использовании API операционных систем следует выбирать варианты функции, которые работают с многобайтными кодировками. Однако, перед использованием, к примеру, WinAPI-функций, UTF-8 строки нужно перекодировать в UCS-2 (примерно совпадает с UTF-16). Что же касается вывода UTF-8 строк в консоль, нужно смотреть свойства консоли. Если консоль работает непосредственно с UTF-8, то никаких преобразование не требуется (современные консоли GUI, или при определенных настройках, системные консоли *nix). Что касается вывода в "консоль" (хотя она не является таковой) русифицированной Windows - там cp866. Соответственно, требуется перекодировка. Тут два варианта: 1) Использовать возможности Windows (пример) 2) Использовать возможности С++ (пример) Ну вот как-то так. |
|
Сообщ.
#8
,
|
|
|
|
Цитата FasterHarder @ Ну последняя же. Кириллица (DOS), 866-ая. И никаких локалей.Какую из списка кодировку нужно поставить + всякие setlocale никак не мешают здесь? JoeUser, от UTF-8 больше проблем. Хотя бы из-за sizeof(char[]) != strlen(char[])+1. Я, вон, где-то выкладывал обобщённую функцию сортировки многобайтовой строки, там на целый экран манипуляций с символами. |
|
Сообщ.
#9
,
|
|
|
|
Цитата Qraizer @ JoeUser, от UTF-8 больше проблем Повторюсь - есть плюсы, есть минусы. Строки с символами переменной длины хуже парсятся, сортируются - это минус. Но хорошо экономят пространство хранения, обеспечивая широкий набор глифов - это жирный плюс (допустим по сравнению с UTF-32). Что же касается обработки большого объема данных, так, имхо, их нужно не самому решать - а возложить это на SQL БД. Добавлено ЗЫ: Нет, не отрицаю, если речь идет о создании софта для местного рынка или для себя, и не нужно, к примеру, использовать какое-то расширенное оформление - можно и не заморачиваться, а взять по старинке cp866. |
|
Сообщ.
#10
,
|
|
|
|
Цитата Qraizer @ Ну последняя же. Кириллица (DOS), 866-ая. И никаких локалей. да, это кодировка решила все проблемы  спс спспротестил на этом примере: #include "stdafx.h" #include <stdio.h> #include <conio.h> int _tmain(int argc, _TCHAR* argv[]) { printf(" ╔═════╦════════════════════╦════════════════════╗\n");// ╚╔ ╩ ╦ ╠ ═ ╬ ╣ ║ ╗ ╝ printf("Привет, мир!"); getch(); return 0; } вывод: Прикреплённая картинка
кстати, это кодировку я проверял на исходом проекте: русский текст печатался кракозябрами, а псевдографиками - вопросами. А вот новый проект(код чуть выше) отработал на ура без всяких локалей. Ведать что-то там сбилось в исходном проекте. В общем, нужно СРАЗУ при создании проекта переходить на эту кодировку и все, проблем не будет. Хотя, нужно проверить, считывает ли русский текст с клавиатуры правильно (не придется ли переключаться на кодировку 1251)... Добавлено проверил. считывается русский текст отлично. В общем НАДО СРАЗУ СТАВИТЬ ЭТУ КОДИРОВКУ ДА И ВСЕ! |
|
Сообщ.
#11
,
|
|
 |
Цитата FasterHarder @ В общем НАДО СРАЗУ СТАВИТЬ ЭТУ КОДИРОВКУ ДА И ВСЕ! Это, как бы, тебе повезло. А если нужно получать строки из Linux или наоборот - слать туда ? Чаще всего у Виндус используется 4 кодировки - utf16, utf8, CP1251, CP866. Штатными средствами Виндус можно преобразовать любую из них в любую из них. |
|
Сообщ.
#12
,
|
|
|
|
чтобы не создавать новую тему напишу здесь, т к появилась проблема, связанная с кодовой страницей и псевдографикой в коде
из вышенаписанного было понятно, чтобы каркас таблицы нормально отображался нужно ставить кодировку "Кириллица ДОС - 866" и все круто работало. но вот сегодня появилась проблема с настройкой ЗАГОЛОВКА консольного окна вывода // настройка заголовка консольного окна static const TCHAR* title = TEXT("Это заголовок консольного окна вывода русскими буквами"); SetConsoleTitle(title); и вместо русских символов отображаются кракозябры( как это побороть??? зы: а вообще с кодировкой можно хапнуть лютые проблемы на ровном месте, как я понял. Всякие ЮТФ-8, ЮНИКОД и пр. пр. ужс... |
|
Сообщ.
#13
,
|
|
|
|
И снова отсылаю к кодировке .c-файла. Был же совет об использовании 866 страницы. Шрифт, используемый в окне, будет использоваться и в заголовке. Возможно, влияет версия консоли, но это надо в разделе WinAPI уточнять.
P.S. Если приложение юникодовое, то TEXT() по идее правильно сработает на тексте в кодировке 1251 страницы, т.к. именно на это рассчитывает компилятор, когда char[]ный литерал будет компилить в wchar_t[]шный. |
|
Сообщ.
#14
,
|
|
|
|
у меня псевдографика табличная в приложении, поэтому сразу при создании проекта выставил 866 кодировку и не прописывал всякие setlocale, SetConsoleCP, ... и все было зашибись, пока не попытался сделать русскими заголовок консольного окна
проверил на кодировке 1251, да, там заголовок из РЯ правильно отображается от этого ВИНАПИ никуда не деться) но там такая шняга непонятная) потребуются десятки тысяч лет, чтобы выучить винапи ладно, придется значит отказаться от русских букв в заголовке, когда кодировка страницы 866 стоит. ведь псевдографика редко, когда требуется... |
|
Сообщ.
#15
,
|
|
|
|
Цитата FasterHarder @ Значит приложение юникодное. Сделай тогда принудительный ANSI-вызов. Типа:проверил на кодировке 1251, да, там заголовок из РЯ правильно отображается static const char* title = "Это заголовок консольного окна вывода русскими буквами"; SetConsoleTitleA(title); |
0 пользователей читают эту тему (0 гостей и 0 скрытых пользователей)
0 пользователей:
[ Script execution time: 0,0954 ] [ 23 queries used ] [ Generated: 20.04.24, 03:03 GMT ]