
 Алгоритм распознавания речи
, выбор алгоритма
Алгоритм распознавания речи
, выбор алгоритма
|
Наши проекты:
Журнал · Discuz!ML · Wiki · DRKB · Помощь проекту |
||
| ПРАВИЛА | FAQ | Помощь | Поиск | Участники | Календарь | Избранное | RSS |
| [3.139.238.76] |

|
|
Алгоритм распознавания речи
, выбор алгоритма
|
Сообщ.
#1
,
|
|
|
|
Есть проблема выбора алгоритма распознавания речи, необходимо произвести анализ имеющихся алгоритмов и выбрать какой-то, и как результат представить программу, которая распознаёт несколько фиксированных слов от конкретного человека т.е. можно дикторозависимую.
Основных алгоритмов как я понял(может ошибаюсь) два. Один изложен на сайте http://speech-text.narod.ru/ с предварительной цифровой обработкой и поиском по технологии СММ. Второй с помощью фонем, как я понял наиболее сложнореализуемый, но эффективный. Какой алгоритм лучше использовать? Или есть более простые алгоритмы? |
|
Сообщ.
#2
,
|
|
 |
Если задача создать программу, распознающую несколько (несколько десятков или сотен) слов или фраз, то проще всего сделать это с помощью нейросетей. Причём можно сделать дикторонезависимую (если обучить на нескольких разных голосах).
|
|
Сообщ.
#3
,
|
|
|
|
Нужно и программу создать и провести анализ алгоритмов (наиболее развитые, перспективные, пока не реализумые). Обосновать выбор исходя из конкретного задания (достаточно одного диктора и около десятка или двух слов)
А какую нейросеть использовать?есть ли бесплатные разработанные сети, которые можно использовать? Я просто с нейросетями встречался около двух лет назад на лабах и все. |
|
Сообщ.
#4
,
|
|
|
|
Цитата rommag @ провести анализ алгоритмов (наиболее развитые, перспективные, пока не реализумые). Наиболее развитые алгоритмы сейчас на основе СММ. Наиболее перспективные - на нейросетях. Пока не реализованые - алгоритмы выделения инвариантных признаков. Алгоритмы будущего - распознавание образов нейросетями, способными выделять инвариантные признаки образов (т.е. признаки, не зависящие от масштабов, поворотов, временных, частотных, пространственных вариаций и искажений). Для решения задачи распознавания десятка-двух слов проще всего взять персептрон с одним скрытым слоем. В качестве признаков можна взять спектральные или кепстральные коэфициенты (можно еще и их производные). Для обеспечения инвариантности (чтобы на даный вход сети подавался даный признак)нужна автоматическая сегментация слов. Проще всего равномерная. Но лучше сегментация на фонемы. Ещё лучше определение точек перехода согласный-гласный. Признаки берутся на определённых расстояниях от этих точек (больше на гласной). В выходном слое взять столько нейронов, сколько нужно распознать слов. Во входном - максимальное число сегментов умножить на количество признаков в одной точке и умножить на количество точек (в которых вычисляются признаки) в сегменте. Число нейронов скрытого слоя нужно подбирать экспериментально. Для обучения сети нужно создать (надиктовать) несколько наборов из всех слов. Для обучения сети можно использовать или готовые сети з обратным распостранением, или самому написать. Ну а для распознавания алгоритм такой: 1.С определенным шагом вдоль сигнала вычисляете признаки сегментации. 2.Автоматическая сегментация слова (равномерная или на фонемы, слоги, дифоны...) 3.Вычисление признаков распознавания в определённых местах сегментов.(это могут быть такие же как и для сегментации) 4.Набор признаков подаёте на вход сети. 5.На выходе находите нейрон с максимальным значением. |
|
Сообщ.
#5
,
|
|
|
|
Анатоль, Вы описали алгоритм "распознавания речи".
Почемы-бы Вам не проделать все эти операции и не предоставить работающую программу? Думаю, что проблема в том, что это ни у кого, к сожалению, не получилось. Вот Вы говорите - "нейрон" и по Вашему - это персептрон. Забавно. Вы застряли годах в 50-60 прошлого века. Нет, если получится, я только за и буду просто счастлив, что имел удовольствие читать Ваши посты одним из первых. Это не сорказм, честно. Ну хорошо, есть Speech API 5 и еще много чего и что изменилось ? Прорыв? Нет, просто эволюция. |
|
Сообщ.
#6
,
|
|
|
|
Цитата shur_nn @ Анатоль, Вы описали алгоритм "распознавания речи". Ну, это сильно сказано. Я всего лиш сказал, как сделать простенькую програмку для распознавания десятка-двух слов или фраз. Цитата shur_nn @ Почемы-бы Вам не проделать все эти операции и не предоставить работающую программу? Я давно это проделал. Такую програмку можете посмотреть на моем сайте (http:\\proekt-ai.kh.ua). Называется "Вася". Цитата shur_nn @ Думаю, что проблема в том, что это ни у кого, к сожалению, не получилось. "Вася" распознаёт свои фразы очень хорошо. Любым голосом, даже шепотом. Кроме того он может говорить. У него есть свой синтезатор. Это простенькая диалоговая програмка. (Язык украинский). Цитата shur_nn @ Вот Вы говорите - "нейрон" и по Вашему - это персептрон. Забавно. Вы застряли годах в 50-60 прошлого века. Персептрон состоит из нейронов. В 50-60 годах ещё не умели обучать многослойних персептронов (со скрытым слоем). Алгоритм обратного распостранения ошибки появился в 80-тых. Кроме того я не говорил, где я застрял, а только как можно сделать простую програмку для распознавания нескольких десятков слов (фраз). |
|
Сообщ.
#7
,
|
|
|
|
Очень заинтересовался "Васей". Жаль, что только по украински.
Ну да ладно, вроде понятно. В конце концов у меня друг с украины, поможет. Попробую немедленно потестить. Если все так, как Вы описали, почему нет релиза №2 и т.д.? Или при большем числе распознаваемых слов начинаются проблемы ? И над чем сейчас Вы работаете ? Добавлено Потестил. У меня обычная китайская гарнитура. Ни при каких уровнях чувсвительности микр. не сумел добиться распознавания ни одного слова  К сожалению в основном распознается "Дурная машина" и "Пить будешь". Может я как-то не так изпользую программу ? Если нетрудно, опишите как ей пользоваться. На других программах распознавания хотя-бы 50 на 50 было. |
|
Сообщ.
#8
,
|
|
|
|
Цитата shur_nn @ Или при большем числе распознаваемых слов начинаются проблемы ? Я пробовал и на 300 слов (фраз) но только на свой голос. (совести не хватало других людей заставлять 300 фраз записывать). Работало нормально. Цитата shur_nn @ почему нет релиза №2 и т.д.? Нет смысла. Обучениение на целые слова (фразы) не перспективно. Слишком много слов в языке. Перспективней обучать распознавать слоги, дифоны. Их меньше. Цитата shur_nn @ И над чем сейчас Вы работаете ? Хочу создать психоакустическую модель звуков речи. В которой бы были постоянные параметры, характеризующие даный звук (дифон), параметры, задающие просодику (темп, интонации...) и параметры индивидуального голоса. Если б такую модель удалось создать, то можно было бы синтезировать любой голос (задав только параметры индивидуальности), распознавать звуки речи (выделяя из речи параметры дифонов), идентифицировать диктора... Цитата shur_nn @ У меня обычная китайская гарнитура. Я пробовал Васю с разными микрофонами. Он работал и с самыми дешёвыми. Цитата shur_nn @ Ни при каких уровнях чувсвительности микр. не сумел добиться распознавания ни одного слова Был бы благодарен Вам, если б Ви записали и выслали мне образцы тех фраз Вашим голосом. (wave, 11кгц. 8 бит. моно) на ящик ant54@yahoo.com Я посмотрел бы в чём там дело. Цитата shur_nn @ Если нетрудно, опишите как ей пользоваться Слабым местом Васи является то, что любой шумок, щелчёк он воспринимает за начало фразы и начинает "распознавать". Т.е. с ним надо работать в относительной тишине. Попробуйте отключить голосовой ответ Васи что б не мешал (меню "Голос(-) ). Обратите внимание на осцилограмму. Правильно ли определяется начало и конец фразы (между вертикальными серыми линиями). Правильно ли сделана сегментация (между красными и зелёными вертикальными линиями - гласные.) Цитата shur_nn @ На других программах распознавания хотя-бы 50 на 50 было На всех голосах, что я пробовал, распознавание было 100%. (осечки были только в тех случаях, когда распознавание запускалось не настоящим началом фразы, а каким-то шумом) |
|
Сообщ.
#9
,
|
|
|
|
Снова попробовал, но результат неудовлетворительный.
Судя по тому, что Вы описали, проблема в шумах. Мой ноут (Asus F3Jseries) ловит помеху 50 Гц, как со встроенного микрофона, так и с микрофона гарнитуры. С самого начала использования ноута эта проблема присутсутсвовала. Мне она особо правда не мешает, даже наоборот. Судя по всему Ваша программа неустойчива к шумам и случайным помехам. И Вы сами описали отчего, неправильно определяется начало распознаваемого фрагмента. Скорее всего в основе корреляционный алгоритм. Подобные проблемы вполне предсказуемы. Думаю, что программа будет сильно ошибаться и на образцах с разной скоростью произнесения. Кто-то говорит быстрее, кто-то медленнее и т.д. Добавлено По поводу создания модели различных голосов - видимо об этом пока рано думать. Проблема полноценного распознавания даже отдельных комманд - нереализована пока никем. Мне, например была поставлена задача: создание на базе терминала оплаты услуг речевого интерфейса. Требования - уверенное распознавание цифр (от 0 до 9) в условиях посторонних шумов (торговый центр). Цель - ускорить процесс оплаты услуг, за счет простого произнесения номера телефона, номера договора, счета, суммы. Работа расчитана на год, оплата по итогам тестирования программы. Договор практически словесный, поскольку ни я ни клиент не готовы заключить юридически обязыающий договор. "Низы не могут, верхи не хотят".  Я провел свое ислледование. Опробовал множество существующих программ, коммерческих, любительских. Результат -> 0. Ни одна программа не способна справиться с этой, казалось-бы, элементарной задачей. Даже цирковые собаки способны на подобные фокусы Сейчас разрабатываю свою модель распознавания. Как обычно голый энтузязизм |
|
Сообщ.
#10
,
|
|
|
|
Цитата shur_nn @ Мой ноут (Asus F3Jseries) ловит помеху 50 Гц, как со встроенного микрофона, так и с микрофона гарнитуры. Сетевую наводку можно на порядок уменьшить, коснувшись рукой металлической части компютера. Но Вася на 50 гц. не реагирует. Там от каждого значения вычитается смещенное на пол периода для 50 гц. Проблему с неправильным определением начала фразы впринципе можно решить радикально - вообще не определять. А непрерывно проводить сегментацию и распознавание сегментов и их последовательностей. Нужна ли психоакустическая модель звуков речи? Нужна в любом случае. В явном, или неявном виде. При обучении на большом количестве примеров программа (нейросеть, СММ...) создает такую модель в неявном (скрытом от человека) виде. Но модель в явном виде была бы в вычислительном плане намного эфективней. В ней не было бы лишних параметров. Ведь при создании модели обучением нужно заложить огромное число свободных параметров, и убрать лишние в обученой модели задача очень сложная. |
|
Сообщ.
#11
,
|
|
|
|
По сути Вы приверженец пофонемного распознавания. Я например то-же.
На мой взгляд, обучать псевдо нейросеть, пустая трата времени. Их обобщая способность на много порядков ниже человеческой, возможно гораздо эффективнее и быстрее разобраться самому в обрабатываемых данных. По природе мы все лентяи. Пусть лошадь думает, у нее голово большая |
|
Сообщ.
#12
,
|
|
|
|
Цитата shur_nn @ По сути Вы приверженец пофонемного распознавания Я бы сказал: посегментного. Нужно брать сегменты большие, чем фонемы. Отдельные фонемы в речи распознать невозможно. Даже человеку. В быстрой речи даже отдельные слоги невозможно распознать. Цитата shur_nn @ возможно гораздо эффективнее и быстрее разобраться самому в обрабатываемых данных Разбираются уже лет 60... Надо уловить какую-то закономерность, построить модель со свободными параметрами и обучением на образцах речи вычислить эти параметры. Чем лучше мы будем понимать психоакустические закономерности, чем удачнее построим модель (с минимальным количеством параметров) тем эфективней она будет работать. |
|
Сообщ.
#13
,
|
|
|
|
По поводу N лет, Вы в самую точку. Традиции не всегда хорошо.
Есть естественный отбор и эволюция. Естественный отбор - это когда идет отбор наилучших качеств. Эволюция - скачкообразный процесс, приводящий к новым качествам. Практически всё по Дарвину. Эволюции алгоритмов в распознавания речи пока нет, есть естественный отбор. Значит нужен поиск других методов и подходов. Я уже писал в других ветках о применении методов нелинейной динамики к распознаванию речи. У меня уже есть очень хороший результат. Сейчас дорабатываю метод и пишу простенькую (пока) программку речевого калькулятора. Без конкретного результата я бы и не стал так настаивать. Анатоль, советую и Вам изучить направление в области нел. динамики - моделлирование по временным рядам. В этой области уже достаточно наработано, для создания эффективных алгоритмов распознавания образов. Пока математики смакуют "новую игрушку", инженеры должны ее использовать. |
|
Сообщ.
#14
,
|
|
|
|
Цитата shur_nn @ Я уже писал в других ветках о применении методов нелинейной динамики к распознаванию речи. Что єто за зверь такой? Не могли бы Ви рассказать о "физической" сущности метода. Без математики. Что там обрабатывают, сигнал, спектр, кепстр? Что обучают распознавать, фонемы, дифоны, слоги, слова? |
|
Сообщ.
#15
,
|
|
|
|
Физическая сущность проста и понятна. Совсем без математики конечно трудно объяснить.
Вы наверное слышали о дифференциальных уравнениях. Вся физика на них построена, начиная от механики и кончая квантовой физикой. Физический смысл диф. уравнения установить взаимосвязь между существенными параметрами влиящими на процесс. Фактически установив вид уравнения Вы получаете модель реальной системы. Определив начальные условия уравнения Вы получаете текущее состояние системы. Диф. уравнение по сути и есть мат. аналог реальной системы. Определив начальные условия и вид уравнения можно предсказать поведение реальной системы на некоторый интервал времени (горизонт предсказания). По сути - это и есть распознавание, идентификация системы, явления, процесса. Физический смысл диф. уравнений заложен в их структуре и они определяют закон по которому развивается система. Создания диф. уравнения очень сложный процесс, фактически это и есть открытие нового закона и являлось во все времена уделом избранных. Сейчас появилась возможность реконструировать диф. уравнение по временной реализации параметров, полученных в результате измерения реального процесса. Это стало возможно благодаря развитию собственно компьютеров, а также математики. Я к сожалению не могу Вам в рамках данного общения объяснить все, что уже наработано в данной области. Могу только дать ссылки на литературу в интернете. При желании Вы без труда и сами можете найти информацию на эту тему. Задайте например поиск в гугле - методы глобальной реконструкции, или например реконструкция отображений по временному ряду. В своем алгоритме для распознавания речевой комманды я использовал явление синхронизации системы. В качестве значимых параметров выбрал амплитуду и частоту сигнала. Построив отображение реального звука (слова) я получил модель, которая циклически воспроизводит данный процесс. Далее, подмешивая входящий с микрофона сигнал в уравнение модели получаю отклик. Если есть соответствие модели и входного сигнала, то в этом случае отклик модели максимален. Основное преимущество данного подхода в том, что явление синхронизации обладает свойствами обобщения и позволяет выделять схожесть модели с входным сигналом по признакам функциональной схожести, а не конкретной реализации. Допишу программку на Си, обязательно сброшу. Сейчас пока все результаты в маткаде. |
|
Сообщ.
#16
,
|
|
|
|
Вы хорошо рассказали об диф. уравнениях. Но дальше все непонятно.
Цитата shur_nn @ В своем алгоритме для распознавания речевой комманды я использовал явление синхронизации системы. Что за система? Что такое явление синхронизации системы? Цитата shur_nn @ В качестве значимых параметров выбрал амплитуду и частоту сигнала. Что Вы подразумеваете под амплитудой сигнала? Мгновенную амплитуду? Значение сигнала в каждом семпле? А что такое частота сигнала? Голосовой сигнал имеет целый спектр разных частот. Что за частоту Вы берёте, как ее получаете из сигнала? Цитата shur_nn @ Построив отображение реального звука (слова) я получил модель, которая циклически воспроизводит данный процесс Вы проводите какие-то математические действия на сигалом слова. В чём их суть, смысл? В результате какого-то преобразования сигнала получаете какой то его образ, модель. Откуда у Вас уверенность, что эта модель моделирует существенные стороны звуков слова? Если бы Вы построили свою модель на основании многих реализаций этого слова разными голосами, то у Вас ногла бы быть надежда, что Ваше хитрое преобразование может выделить общее, существенное и отбросить частное. Цитата shur_nn @ Далее, подмешивая входящий с микрофона сигнал в уравнение модели получаю отклик. Ну это как я понимаю сравниваете данный образей звука с эталоном, с моделью. Цитата shur_nn @ Основное преимущество данного подхода в том, что явление синхронизации обладает свойствами обобщения и позволяет выделять схожесть модели с входным сигналом по признакам функциональной схожести, а не конкретной реализации. Что же это за явление такое таинственное, которое обладает таким замечательным свойством, и о котором Вы совершенно ничего не рассказали? |
|
Сообщ.
#17
,
|
|
|
|
Проблема в терминологии.
Система - некий объект, который мы исследуем. Например речевой тракт человека. То-же можно сказать и о мат. модели. Процесс - последовательность смены состояний системы, которые мы фиксируем в виде временного ряда измеряемых величин. Отображение - фактически диф. уравнение системы (мат. модель) с той лишь разницей, что в диф. уравнении функция dx/dt - имеет бесконечное разрешение т.к. dt->0, а в модельном отображении мы имеем дело с дискретным временем. Соответствено обыкновенное диф. уравнение преобразуется к виду X(i)=F(X(i-1)). F - некий оператор эволюции системы. Собственно F и есть модель, которую необходимо получить по измеряемой временной последовательности. Еще раз говорю Вам, что данный вопрос довольно сложен и для его понимания Вам необходимо изучить соответствующую литературу. По поводу таинственной синхронизации, поищите в интернете темы - стахостическая синхронизация, аттрактор системы, бассейн притяжения. В этом форуме есть созданная мной тема - синтез речи при помощи звукового редактора. Собственно это есть указание на то, какие основные параметры я использовал для построения модели. |
|
Сообщ.
#18
,
|
|
|
|
Есть еще вопрос. Каким образом можно улучшить распознавание, если программа дикторозависимая, т.е. создается под конкретного человека? Может можно что-то сделать еще на этапе обработки сигнала или при получении например коэффициентов MFCC?
|
|
Сообщ.
#19
,
|
|
|
|
Цитата rommag @ Каким образом можно улучшить распознавание, если программа дикторозависимая Скорее, наоборот - если программа дикторонезависимая, то можно что-то сделать с помощью нормализации и адаптации. Специальные приёмы для дикторозависимых систем трудно представить. |
|
Сообщ.
#20
,
|
|
|
|
Итак, что изменилось за это время? Как успехи?
Почему же человек легко узнает слова, произнесенные другими людьми, искаженные, с фоном. А компьютер неспособен на это? Чуть быстрее, чуть медленнее, под музыку - все ступор. shur_nn! Давай литературу, пожалуйста! Мне же кажется, проблема еще вот в чем. Давайте вспомним анатомию слухового анализатора. У млекопитающих орган слуха (внутреннее ухо) представляет собой полость в форме улитки. Внутри полости, спирально "натянуты" волоски рецепторов, причем разной длинны, каждый из этих волосков чувствителен к определенной частоте в диапазоне от 20 до 20 тыс Гц. (разумеется, вы знаете, что наибольшую чувствительность человек имеет в "речевом" диапазоне 1200 - 6800 Гц). Каждый волосок сязан с биполярным нейроном, который (вероятно) решает, какой силы сигнал пропустить, какой "отбраковать". Из аксонов биполярных нейронов состоит слуховой нерв. Т.е. по нему постоянно передается информация о частотном составе. Далее эти аксоны идут к кохлеарным ядрам продолговатого мозга, где их ждет переключение второй нейрон (не знаю, что он конкретно делает с сигналом), затем акстоны от второго нейрона идут к третьему (к медиальному добавочному оливному ядру и трапецевидному телу), причем 70% волокон переходят от второго нейрона на противоположную сторону, 30% остается на той же стороне. Отходя от третьего нейрона, волокна оканчивается в нижних холмиках крыши среднего мозга и в медиальном коленчатом теле (4 нейрон). Длительный путь оканчивается в 5 нейроне слуховой коры (Зона Гешле) Так вот, в этой хитрой схеме нет ни одной лишней детали (иначе эволюция давно бы их отбросила). Каждый переход от рецептора улитки до 5 нейрона связан с каким-то фундаментальным преобразованием информации с каким? я знаю только первый этап. Всего их не меньше пяти и все они функционируют единовременно, по мере поступления сигнала, без видимых "фреймов" 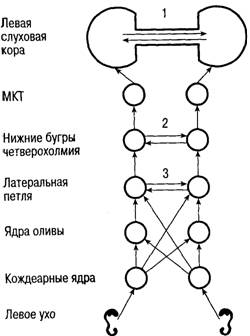 Слуховая система имеет не только много уровней, но и большое число перекрестных комиссур, благодаря которым каждое ухо проецируется в оба полушария мозга: 1 — мозолистое тело; 2 — комиссура нижних бугров четверохолмия; 3 — комиссура Пробста Есть еще вариант, что от всех(или почти) биполярных клеток "запитывается" каждая нейронная колонка в слуховой коре. Каждая колонка узнает свой образ. Но это не точно. |
|
Сообщ.
#21
,
|
|
|
|
Основые алгоритмы, которые нужно рассмореть для пословного распознавания:
1. Метод динамического программирования 2. Нейронные сети 3. Марковские модели. Но перед применением этих алгоритмов необходимо провести первичную обработку речевого сигнала 1. Ввод речевого сигнала 2. Нормализация 3. Преобразование Фурье примеры алгоритмов на Delphi есть на сайте http://signals.freezoka.com Дальше, если нужно, проводится сегментация и непосредственно распознавание. Самый простой алгоритм для реализации это метод динамического программирования. |
|
Сообщ.
#22
,
|
|
|
|
Цитата digitizer @ Основые алгоритмы, которые нужно рассмореть для пословного распознавания: Дальше, если нужно, проводится сегментация и непосредственно распознавание. Самый простой алгоритм для реализации это метод динамического программирования. Интересует по-фонемное распознавание, слова - прерогатива корковых структур. Да и нужна ли сегментация? Живой анализатор разве сегментирует? Специализированные цепочки выделяют из потока сигнала каждый свою фонему, передают возбуждение выше, на колонки, а те суммируют их и передают в кору образ. Происходит это непрерывно 24 часа в сутки. Вопрос, как это реализовано? Может кто нибудь предоставить специализированную программу распознающую фонему "А" или "Ш" независимо от диктора, громкости, скорости и окружения? |
|
Сообщ.
#23
,
|
|
|
|
Анатоль
Не мог бы ты предоставить сорцы своей программы распознавания? Я начал интерисоваться темой распознавания речи. Хотел бы поглядеть как устроена твоя программа, чтобы начать писать свою. |
|
Сообщ.
#24
,
|
|
|
|
Цитата Ungedonist @ Не мог бы ты предоставить сорцы своей программы распознавания? А что такое "сорцы"? |
|
Сообщ.
#25
,
|
|
|
|
Цитата Анатоль @ А что такое "сорцы"? Исходные тексты программ  |
|
Сообщ.
#26
,
|
|
|
|
Ungedonist
А что Вас интересует, весь исходник, или какой-то момент? |
|
Сообщ.
#27
,
|
|
|
|
Цитата Анатоль @ Ungedonist А что Вас интересует, весь исходник, или какой-то момент? меня интерисует как из непрерывного потока выбираются слова и распознаются они ведь всегда разные по длительности |
|
Сообщ.
#28
,
|
|
|
|
Цитата Ungedonist @ как из непрерывного потока выбираются слова и распознаются они ведь всегда разные по длительности Я это пробую делать с помощью предварительной (автоматической) сегментации (на слоги, фонемы). Когда известны границы (или средины) фонем, то разная их длительность не является проблемой. |
|
Сообщ.
#29
,
|
|
|
|
Цитата Ungedonist @ меня интерисует как из непрерывного потока выбираются слова и распознаются они ведь всегда разные по длительности Динамическое программирование (оно же Витерби) используется для одновременного декодирования и точного нахождения акустических состояний во времени |
|
Сообщ.
#30
,
|
|
|
|
Цитата Анатоль @ Я это пробую делать с помощью предварительной (автоматической) сегментации (на слоги, фонемы). Когда известны границы (или средины) фонем, то разная их длительность не является проблемой. Согласен, можно разделить на сегменты! Но для каждого отдельного случая длительность ыонемы своя. Как действовать в этом случае? Пусть программа распознаёт несколько слов, тогда она должна узнавать их именно по последовательности фонем? То есть надо для каждого слова хранить ещё и последовательность фонем в слове? |
|
Сообщ.
#31
,
|
|
|
|
Цитата Ungedonist @ То есть надо для каждого слова хранить ещё и последовательность фонем в слове? Вы о транскрипции? Ну да. Или хотя бы иметь правила, как эту(эти) последовательность получить. |
|
Сообщ.
#32
,
|
|
|
|
Можно взгдянуть на то, как у тебя реализовано распознавание речи, начиная от самого начала?
Так будет наглядней, понятнее. А то я наверно тебе уже надоел своими вопросами |
|
Сообщ.
#33
,
|
|
|
|
Ungedonist
А Вы выложите тут свою распознавалку? |
|
Сообщ.
#34
,
|
|
|
|
Цитата Анатоль @ Ungedonist А Вы выложите тут свою распознавалку? Когда всё сделаю, тогда выложу! Быть может, это кому-то поможет. Данная тема является темой моего диплома, вот и хочу сделать что-то стоящее) |
|
Сообщ.
#35
,
|
|
|
|
Ну что ж, давайте сделаем такой прецедент.
Может ещё кто-то поддержит. Даю исходник "Васи".(REC42U.zip) Прикреплённый файл  Rec42U.zip (7.11 Кбайт, скачиваний: 804) Rec42U.zip (7.11 Кбайт, скачиваний: 804)
|
|
Сообщ.
#36
,
|
|
|
|
большое спасибо
|
|
Сообщ.
#37
,
|
|
|
|
Анатоль
А почему Вы считаете, что будущее распознавания за нейросетями? Потому что это мат. модель мозга? Я тут пытаюсь понять вышеописанную Вами модель НС для распознавания звука. Пока не очень получается понять, что там на входном слое.. Поможите? Цитата Анатоль @ Во входном - максимальное число сегментов умножить на количество признаков в одной точке и умножить на количество точек (в которых вычисляются признаки) в сегменте. Совершенно не понятно как собираеются вот эти признаки.. Вообще, что тут имеется ввиду под признаками? Мощность сигнала на всех частотах звукового спектра? (чтобы таких частот не было слишком много - можно по порогу, наиболее мелкие отсеять, чтобы исключить незначительные, слабые частоты.. верно?). Получается, мы выбираем участок звука (который Вы называете сегментом, да?) и собираем что ли все его признаки/мощности на протяжении всего звукового сегмента? |
|
Сообщ.
#38
,
|
|
|
|
Цитата Black*Eternal @ Пока не очень получается понять, что там на входном слое.. Единицей распознавания является целая фраза. Она разбавается (автоматически) на сегменты (слоги). Пусть ns - максимальное количество сегментов (в самой длинной фразе). В каждом сегменте выбираем нек. количество точек, в которых вычисляем параметры. Пусть nt - количество таких точек в сегменте. В каждой такой точке вычисляем нек. акустические параметры. Это какие-то характеристики огибающей спектра. (Спектральные коэфициенты в шкале барк или мелл или какие-то их комбинации) Пусть np - количество таких параметров. Тогда общее количество чисел, поступающих на вход сети будет N=ns*nt*np |
|
Сообщ.
#39
,
|
|
|
|
А что значит, что фраза разбивается автоматически на слоги? А как она сама может разбиваться? Всмысле, определённым алгоритмом мы её разбиваем?
Я думал на вход - слог подавать предварительно уже выделенный из фразы/очередного слова.. |
|
Сообщ.
#40
,
|
|
|
|
Цитата Black*Eternal @ Я думал на вход - слог подавать предварительно уже выделенный из фразы/очередного слова.. Я тоже сейчас об этом подумываю. Но в "Васе" на вход сети подаются одновременно все слоги фразы (предварительно выделенные). (Т.е. нек. акустические параметры из этих слогов). |
|
Сообщ.
#41
,
|
|
|
|
Ну проще-то во всяком случае пока что распознавать только слог, а потом уже подключать сегментацию слов на слоги..
Наверное так я и поступлю по началу, а потом уже буду думать как улучшать это дело. А для распознавания слога на вход НС чего нам подать нужно? Звуковой спектр этого слога? Это будет выглядеть как двумерный массив - по строчкам например индексы отсчётов, а по колонкам соответственно частоты и их мощность.. получается трёхмерный массив.. хм Кстати, а как это всё в НС затолкать? Добавлено а хотя.. туплю чё-то я. Берём на входы и прямо на все подаём весь спектр звука, соответственно на каждый вход - мощность очередной частоты. Предварительно видать прийдётся нормировать значения мощности на отрезок -1, +1 или какой-то такой. Не помню уже какой диапазон чисел с какими активационными функциями работает. Посмотрим. |
|
Сообщ.
#42
,
|
|
|
|
Сегментация всё-таки нужна.
Нужна точка перехода согласной в гласную. А потом от этой точки можно взять по штук 3-5 точек влево и вправо. И для каждой из них вектор параметров. И это будет надёжной входной информацией для определения дифона. Можно, конечно и по другому. |
|
Сообщ.
#43
,
|
|
|
|
Сегментация, всмысле, нужна даже для того случая когда мы подаём на вход один слог и на выходе пытаемся получить ответ, что это за слог?
Пока я не очень понимаю как там можно отслеживать переходы с согласной на гласную и наоборот.. поэтому наверное прийдётся пока что - по другому  Может, очень резкая смена спектровых частот говорит о переходе на следующую букву? Или какие там ещё могут быть особенности? |
|
Сообщ.
#44
,
|
|
|
|
Цитата Black*Eternal @ когда мы подаём на вход один слог и на выходе пытаемся получить ответ, что это за слог? Вы собираетесь вручную определять границы слога? Тогда что Вам мешает вручную задать и границы фонем? |
|
Сообщ.
#45
,
|
|
|
|
Цитата Анатоль @ Вы собираетесь вручную определять границы слога? ну как.. у меня же в начале только один слог и будет на входе а уж позже "когда-нибудь", я буду сегментированием заниматься, чтобы в написанный код эти слоги подавать. А пока что с одним слогом научить бы его.Цитата Анатоль @ Тогда что Вам мешает вручную задать и границы фонем? а зачем их задавать? пусть себе слог распознаёт хотя... скорее всего "затянутые" гласные оно навряд ли распознает тогда? Например: "ба" и "бааааа". Добавлено Кстати... по поводу протяжной буквы. Я вот тяну сейчас букву "а" и смотрю насколько со временем звучания изменяется спектр.. И изменяется, надо сказать, не сильно. В принципе, грубо говоря - один и тот же. Плюс/минус. Таким образом, может все последующие похожие спектры просто не учитывать? Вот получили мы спектр буквы "а" и далее у нас "аааа" всё звучит. А спектр-то почти один и тот же.. и мы далее его просто игнорируем, раз он похожий.. Как такая идея? Добавлено таким образом у нас, что одна "а", что протяжная - будет всего лишь одним спектром представлено, одним всплеском.. Или так проблему "скорости речи" не решить? Добавлено но скорее всего, конечно, не неучитывать надо, а усреднить, я имел ввиду. Добавлено хотя тут походу я говорю об усреднении фонемы, но слог ведь по-любому прийдётся как-то разделить на фонемы... |
|
Сообщ.
#46
,
|
|
|
|
Цитата Black*Eternal @ ну как.. у меня же в начале только один слог и будет на входе Еще тишина будет. Слог от тишины как-то надо отличить. Вручную? |
|
Сообщ.
#47
,
|
|
|
|
Цитата Анатоль @ Цитата Black*Eternal @ ну как.. у меня же в начале только один слог и будет на входе Еще тишина будет. Слог от тишины как-то надо отличить. Вручную? Вполне возможно.. А чего там отличать.. Я смотрю на спектр начиная от -60дБ, при тишине там только 50герцовая частота имеет мощность, остальных нет. Да и разговор (мой например) колышит частоты более 10Гц. Поэтому отличить вроде не сложно будет программно. Другое дело если от какого-то шипения отличать, если оно будет или от шума.. Добавлено Кстати, а зачем нужны базы данных для распознавания? (чуть выше тема есть в прикреплённых с звуковыми файлами надиктованными разными дикторами). Для анализа звучания фонем произносимых разными голосами? Для лучшего обучения? нейросетки, например.. |
|
Сообщ.
#48
,
|
|
|
|
И ещё не понятна вот эта Ваша фраза:
Цитата Анатоль @ Нужно брать сегменты большие, чем фонемы. Отдельные фонемы в речи распознать невозможно. Даже человеку. В быстрой речи даже отдельные слоги невозможно распознать. А почему некоторые фонемы распознать невозможно? Человек проглатывает их? Как звук поменяется, там и фонема изменилась, такое не сработает? |
|
Сообщ.
#49
,
|
|
|
|
Цитата Black*Eternal @ А почему некоторые фонемы распознать невозможно? Будет там какое-то гудение или шумок. Что это такое? В разном контексте это может быть что угодно. В динамике, возможно больше информации, чем в статике. Поэтому желательно куски побольше, чтоб динамику анализировать. |
|
Сообщ.
#50
,
|
|
|
|
Цитата Анатоль @ Будет там какое-то гудение или шумок. Что это такое? Ну мне кажется, хорошо, если оно просто не распознает этот звук.. в лучшем случае. В худшем если распознает  А так, если не распознает - можно хоть догадаться какое это было слово. (по словарю бегать и искать подходящие слова) А так, если не распознает - можно хоть догадаться какое это было слово. (по словарю бегать и искать подходящие слова) |
|
Сообщ.
#51
,
|
|
|
|
Ребят, скиньте хоть какой нибудь работающий исходник с распознованем, мне надо десять слов всего распознать, вот майл prisonsoad@mail.ru, буду очень благодарен!
|
|
Сообщ.
#52
,
|
|
|
|
Здравствуйте, я тут впервой, очень интересует данная тема...
Тут товарищ Анатоль написал про библиотеку, которую он использовал в своей проге, Rozm.dll, что за библиотека? он её сам чтоли написал? Нигде упоминания нету... разобраться по украински пока тоже не получается... На сколько я понимаю все программы для этого, что я видел, делаются на английском речевом движке с изменением транскрипции, поэтому так плохо и получатся расспознавать  Вообще есть у кого-нибудь информация про расспознавание русской речи? На каком движке это делается? Какие библиотеки используются? Или как изменить фонемную транскрипцию английского движка?  Видел программу "Программа пофонемного распознавания речи" rechmm называется (загуглите если что), работает хорошо, лучше всех что я видел, но нету описание кода и самого кода... разработчики тоже врядли поделятся  |
|
Сообщ.
#53
,
|
|
 |
Цитата Roman55555 @ "Программа пофонемного распознавания речи" rechmm называется (загуглите если что), работает хорошо, Работает программа неплохо, но чистого пофонемного распознавания здесь нет. Произнесенное слово "натягивается" на одну из ограниченного списка моделей слов. При произнесении абракадабры, будет подобрано ближайшее слово и произведена разбивка на фонемы. Программе не хватает варианта ответа: "Такого слова в списке нет", выдаваемое в случае, если ближайшее слово ниже заданного порога. |
|
Сообщ.
#54
,
|
|
|
|
Как и обещал Анатолю, выкладываю свой код.
Его код вообще не использовал, программа ещё очень сыра и требует серьёзной доработки. Но может быть кому-нибудь пригодится http://slil.ru/28670569 |
|
Сообщ.
#55
,
|
|
|
|
Цитата Ungedonist @ Как и обещал Анатолю, выкладываю свой код. Его код вообще не использовал, программа ещё очень сыра и требует серьёзной доработки. Но может быть кому-нибудь пригодится http://slil.ru/28670569 Спасибо! Будем ковырять...  Ещё код на C#... Пока не смотрел, может тоже чего полезного... Прикреплённый файл SpeechRecognition.zip (14.34 Кбайт, скачиваний: 547)
|
|
Сообщ.
#56
,
|
|
|
|
Ungedonist, не грузится у меня оттуда Ваш файл.
Почему Вы его здесь не разместите? |
|
Сообщ.
#57
,
|
|
|
|
Подскажите, каков принцип работы систем распознавания речи, которые обучаются не на базе с пофонемной разметкой, а - пословной. Есть ли такие системы вообще?
Что можно почитать по этому поводу? |
|
Сообщ.
#58
,
|
|
|
|
Haze
Dynamic Time Warping - метод распознавания изолированных слов с использованием динамического программирования. |
|
Сообщ.
#59
,
|
|
|
|
MorSe
Спасибо. |
|
Сообщ.
#60
,
|
|
|
|
Так возможно написать маленький модуль, распознающий всего одну фонему но распознающий ее с 90% точностью независимо от пола, возраста, помех и искажений?
|
|
Сообщ.
#61
,
|
|
|
|
Цитата walter-simons @ независимо от помех и искажений Смотря какие помехи и искажения, если вызванные прохождением сигнала через телефонный тракт (или что-то подобное), то 90% точности - реальная число. |
|
Сообщ.
#62
,
|
|
|
|
Искажения типа: голос звучит издалека, идет фоном музыка негромкая или проезжают автомобили. Если это возможно, кто возьмется написать такой модуль, выхватывающий фонему?
|
|
Сообщ.
#63
,
|
|
|
|
Ну это серьёзные искажения и помехи.
При проезжающем автомобиле, из распознавателя будут "выстреливать" фонемы типа Ш, Щ, Ч, С, Х и т.д. При музыке - зависит от музыки, а если ещё и поёт кто-нибудь, то сами понимаете - много ложной тревоги будет, очень много. Провильность 90% - нереальный уровень. Я так думаю. |
|
Сообщ.
#64
,
|
|
 |
walter-simons
Цитата Так возможно написать маленький модуль, распознающий всего одну фонему но распознающий ее с 90% точностью независимо от пола, возраста, помех и искажений? конечно можно,любой человек на это способен.У спектра любой фонемы, есть набор признаков не зависящих от пола и тембра.Из этих признаков можно составить вектор(шаблон признаков фонемы),далее анализировать входящий спектр и если процент подобия векторов выше определённого уровня - значит найдена искомая фонема. |
|
Сообщ.
#65
,
|
|
|
|
Цитата При проезжающем автомобиле, из распознавателя будут "выстреливать" фонемы типа Ш, Щ, Ч, С, Х и т.д. Вы так думаете? Покрышки генерируют человеческие фонемы? или все таки есть разница? Даже если с акустической "точки зрения" разницы нет, мы же не принимаем к сведению шумовые "Ш, Щ, Ч.." Т.е. анализатор, конечно возбуждается, но высший отдел не принимает сигнал без контекста. Мы знаем, что автомобиль ничего нам не "скажет" и игнорируем шум. Я вот какое явление за собой заметил. Мне часто звонят по важным вопросам на мобильный. Мне очень важно не пропустить ни один звонок, поэтому я либо постоянно ношу с собой телефон, либо чутко прислушиваюсь. На мобильном простая мелодия (любая типа MIDI). Так вот, когда в другом источнике появляются отдельные звуки схожие по частоте с моим рингтонам, я сразу же каг-бы слышу что телефон звонил! Более того, когда есть источник сплошного шума (вода из крана) мне кажется, что телефон звонит. Клиника, однако? Нет, "курковая" зона мозга ловит все, что связано с рингтоном и бывает ошибается. |
|
Сообщ.
#66
,
|
|
|
|
Цитата walter-simons @ анализатор, конечно возбуждается, но высший отдел не принимает сигнал без контекста Но сделать программный продукт сделать таким, чтобы он работал как высший отдел человека (тем более не до конца изученный на настоящее время) - это из области научной фантастики Распознаватель фонем часто на месте импульсной помехи пишет "r". Разница вроде бы есть, но программный алгоритм её не видит. Или в слове "БЕТОН" последняя фонема определяется как "М", разница тоже есть, но если последний звук выделить и послушать отдельно от предыдущих, то можно и "М" услышать. Так и в вашем случае, если вырезать участок шума "Покрышки по песку" длительностью как фонема "Ш" в речи и дать наивному слушателю с вопросом: "какая фонема?". То он ответит "фонема "Ш", а не "это не фонема, это шум покрышек по песку". Программы работают гораздо хуже (пока ещё), чем способность распознавания у человека. |
|
Сообщ.
#67
,
|
|
|
|
Можно применить статистическую коррекцию, допустим "М" но слова БЕТОМ нет, есть похожее БЕТОН (90%) следовательно "Бетон". Разумеется, человек еще включает контекстную коррекцию, если речь шла о стройматериалах, он без труда проглотит искажения, если о таре для жидкостей, то вполне воспримет, как "Бидон"
Но в проводить такой анализ, такую дифференцировку не входит в задачи модуля-детектора фонем, пусть он ошибается, пусть дает ложные сигналы иногда. |
|
Сообщ.
#68
,
|
|
|
|
Цитата walter-simons @ Можно применить статистическую коррекцию, допустим "М" но слова БЕТОМ нет, есть похожее БЕТОН (90%) следовательно "Бетон". А если такое распознавание из-за искажения слова "Битум" или "Битым", тогда мы "удалимся" от этих слов, приминив стат. коррекцию. А если диктор специально произносил слово "Бетом" (аббревиатура, спец. термин, жаргон, шифр), тогда мы потеряем такое слово. А в случае слова "Кон" из-за ошибки распознавания получаем другое слово "Ком", стат. коррекция здесь не поможет. |
|
Сообщ.
#69
,
|
|
|
|
Да, возможно, но все это нюансы. Так есть такая программа, кто может написать, хотя бы ради эксперименты?
|
|
Сообщ.
#70
,
|
|
|
|
walter-simons
а зачем интересуетесь? |
|
Сообщ.
#71
,
|
|
|
|
Честно? Хочу инициировать революцию в обработке информации. Без личной выгоды.
|
|
Сообщ.
#72
,
|
|
|
|
конечно без личной выгоды по чужим исходникам легко совершать революции.А вы незадумывались над тем что авторы оригинальных алгоритмов годами собирали по крупицам информацию,проводили бесчисленные опыты и наблюдения,тратили сотни человеко-часов,средства, ломали голову,не спали ночами ворочаясь и стыкуя в голове куски головоломки...и всё это для того чтобы отдать результат просто так?!
|
|
Сообщ.
#73
,
|
|
|
|
Тут дело вот в чем. Рубеж уже близок, вычислительные мощности достаточны для решения этой задачи в "домашних условиях". Лавина уже назрела. Если не мы это сделаем, то сделают другие. Уважаемым авторам остается два пути, либо применить идеологию Open Sourse и стать именами мирового значения. Либо чахнуть над своими находками, пряча их под сукно, а когда необходимость в них отпадет, горестно вздыхать.
|
|
Сообщ.
#74
,
|
|
|
|
Цитата walter-simons @ Лавина уже назрела. Специалистов в области речевых технологий не так уж и много, чтобы говорить о лавине. И с программой, которая "ловит" одну фонему в речи революции не сделать. Уже несколько лет в открытом доступе лежат разработки научных университетов, автоматическое распознавание всех фонем в речи с точностью не хуже 80%. |
|
Сообщ.
#75
,
|
|
|
|
Ну, может и не так много. Я точно не один из них.
Просто попытался "незамыленным" взглядом посмотреть на проблему. Вот как я вижу решение: Звуковой сигнал преобразуют в спектр частот, по аналогии с функцией улитки органа слуха. Полученный поток одновременно предоставляют 43 модулям, каждый из которых настроен на свою фонему, как камертон на свою ноту. Выходной сигнал каждого модуля подается на нейронную сеть ассоциативной памяти. Ну, а память выдает определенный сигал, отражающий данное акустическое явление и даже связь с предыдущими и предсказание последующего события. Как то так. |
|
Сообщ.
#76
,
|
|
|
|
ну если и правда всё так просто , то реализуйте в коде и все дела...
пофонемное распознавание дело нехитрое но есть одно "но",оно дикторозависимое и требует специальных условий и длительной настройки-тренировки под пользователя.А это в свою очередь означает , что практического смысла в таком ПО будет немного...так удовлетворить чисто научный интерес. |
|
Сообщ.
#77
,
|
|
|
|
Цитата пофонемное распознавание дело нехитрое но есть одно "но",оно дикторозависимое и требует специальных условий и длительной настройки-тренировки под пользователя. С такими высказываниями нужно быть осторожнее  |
|
Сообщ.
#78
,
|
|
|
|
Цитата С такими высказываниями нужно быть осторожнее Что конкретно вас смутило?Обоснуйте если не сложно. ага кажется догадался...ну скажем так: пофонемное распознавание дело нехитрое но есть одно "но",оно дикторозависимое(для близкого к 100% опознавания) и требует специальных условий и длительной настройки-тренировки под пользователя. |
|
Сообщ.
#79
,
|
|
|
|
Такой вот вопрос, можно ли с помощью стандартных библиотек некрософта (NetFW, Speechlib) получить пофонемное распознавание?
Сколько не мучаюсь не могу нигде найти такого...Хотя по идее там это должно быть, так как в грамматическом словаре xml можно задавать из каких фонем состоит слово и просто добавлять фонемы... Или вот еще (пока писал вспомнил), можно как нибудь изменить задержку между распознаваемыми словами в этих библиотеках? Если можно, то реально будет прописать все фонемы в словарь и не мучаться...Нашел настроики рекогнайзеров в реестре, там такого нет...??? |
|
Сообщ.
#80
,
|
|
|
|
Отвечаю на свой вопрос
Можно, но частично и через задний проход... С помощью XML правил можно подогнать транскрипцию слов, транскрипция фонем есть в описании MS SDK. Пример XML правил: Цитата <GRAMMAR LANGID="409" LEXDELIMITER="|" WORDTYPE="LEXICAL"> <RULE NAME="1" TOPLEVEL="ACTIVE"> <P>|bender|bandar|b eh n d ae r;</P> </RULE> <RULE NAME="2" TOPLEVEL="ACTIVE"> <P>|baran|baaraan|b aa r aa n;</P> </RULE> </GRAMMAR> Причем если слово в транскрипции разделить менее чем по 3 буквы, то это автоматически будет считаться фонемой... воооооооот... Если надо могу выложить полный код на C# c английскими фонемами. |
|
Сообщ.
#81
,
|
|
|
|
Roman55555! Конечно выкладывай!
|
|
Сообщ.
#82
,
|
|
|
|
Черт, так и знал...
Цитата using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; using System.Drawing; using System.Text; using System.Windows.Forms; using System.IO; using SpeechLib; using System.Collections; namespace SpeechTest { public class Form1 : System.Windows.Forms.Form { private System.Windows.Forms.Button cmdEnable; private SpeechLib.SpSharedRecoContext objRecoContext = null; private SpeechLib.ISpeechRecoGrammar grammar = null; private SpeechLib.ISpeechGrammarRule menuRule = null; private System.Windows.Forms.TextBox txtReco; private TextBox textBox1; private IContainer components; public Form1() { InitializeComponent(); } protected override void Dispose( bool disposing ) { if( disposing ) { if (components != null) { components.Dispose(); } } base.Dispose( disposing ); } private void InitializeComponent() { this.cmdEnable = new System.Windows.Forms.Button(); this.txtReco = new System.Windows.Forms.TextBox(); this.textBox1 = new System.Windows.Forms.TextBox(); this.SuspendLayout(); // // cmdEnable // this.cmdEnable.Location = new System.Drawing.Point(16, 16); this.cmdEnable.Name = "cmdEnable"; this.cmdEnable.Size = new System.Drawing.Size(96, 23); this.cmdEnable.TabIndex = 0; this.cmdEnable.Text = "Enable Speech"; this.cmdEnable.Click += new System.EventHandler(this.cmdEnable_Click); // // txtReco // this.txtReco.Location = new System.Drawing.Point(16, 75); this.txtReco.Name = "txtReco"; this.txtReco.Size = new System.Drawing.Size(590, 20); this.txtReco.TabIndex = 5; // // textBox1 // this.textBox1.Location = new System.Drawing.Point(16, 49); this.textBox1.Name = "textBox1"; this.textBox1.Size = new System.Drawing.Size(590, 20); this.textBox1.TabIndex = 10; // // Form1 // this.AutoScaleBaseSize = new System.Drawing.Size(5, 13); this.ClientSize = new System.Drawing.Size(618, 107); this.Controls.Add(this.textBox1); this.Controls.Add(this.txtReco); this.Controls.Add(this.cmdEnable); this.Name = "Form1"; this.Text = "Speech Test"; this.ResumeLayout(false); this.PerformLayout(); } [STAThread] static void Main() { Application.Run(new Form1()); } private void cmdEnable_Click(object sender, System.EventArgs e) { // Get an insance of RecoContext. I am using the shared RecoContext. objRecoContext = new SpeechLib.SpSharedRecoContext(); // Assign a eventhandler for the Hypothesis Event. objRecoContext.Hypothesis += new _ISpeechRecoContextEvents_HypothesisEventHandler(Hypo_Event); // Assign a eventhandler for the Recognition Event. objRecoContext.Recognition += new _ISpeechRecoContextEvents_RecognitionEventHandler(Reco_Event); //Creating an instance of the grammer object. grammar = objRecoContext.CreateGrammar(0); grammar.CmdLoadFromFile("z.xml", SpeechLoadOption.SLODynamic); grammar.CmdSetRuleIdState(0, SpeechRuleState.SGDSActive); /* ЗАГРУЗКА ИЗ ОБЫЧНОГО ТХТ ФАЙЛА //Activate the Menu Commands. menuRule = grammar.Rules.Add("MenuCommands",SpeechRuleAttributes.SRATopLevel|SpeechRuleAttributes.SRADynamic,1); object PropValue = ""; StreamReader sr = new StreamReader("D:\\trans.txt"); string line; while ((line = sr.ReadLine()) != null) { menuRule.InitialState.AddWordTransition(null, line, "", SpeechGrammarWordType.SGLexical, line, 1, ref PropValue, 0.2F); } grammar.Rules.Commit(); grammar.CmdSetRuleState("MenuCommands", SpeechRuleState.SGDSActive); textBox1.AppendText("!"); */ } private void Reco_Event(int StreamNumber, object StreamPosition, SpeechRecognitionType RecognitionType, ISpeechRecoResult Result) { textBox1.AppendText(Result.PhraseInfo.GetText(0, -1, false)); } private void Hypo_Event(int StreamNumber, object StreamPosition, ISpeechRecoResult Result) { txtReco.AppendText(Result.PhraseInfo.GetText(0, -1, false)); } } } Кстати распознавать стало на порядок лучше... Но проблема осталась старая > распознаются целые слова, а не фонемы, хотя при пополнении словаря слов и написании преобразователя их транскрипций можно достичь похожег о результата... Прикрепил еще в нагрузку транскрипции на англ и перевод на русский (делал сам, так что не обессудьте) Для новичков могу выложить целый проект... ну я думаю разберетесь... Еще чуть не забыл, если в xml правилах задавать фонемы, то только из списка который я дал, иначе вылетит ошибка! Вобщем если будут вопросы пишите - постараюсь ответить... Прикреплённый файл  transcrypt.rar (12.55 Кбайт, скачиваний: 711) transcrypt.rar (12.55 Кбайт, скачиваний: 711)
|
|
Сообщ.
#83
,
|
|
|
|
|
Сообщ.
#84
,
|
|
|
|
Вот еще полезная информация про SDK и вообще.
С помощью следующего кода можно менять лимит загрузки процессора при распознавании, задержку между словами или фразами, адаптацию и пределы расспознавания: Цитата Boolean SRprop; objRecoContext = new SpeechLib.SpSharedRecoContext(); SRprop = objRecoContext.Recognizer.SetPropertyNumber("ResourceUsage", 80); SRprop = objRecoContext.Recognizer.SetPropertyNumber("ResponseSpeed", 200); SRprop = objRecoContext.Recognizer.SetPropertyNumber("ComplexResponseSpeed", 200); SRprop = objRecoContext.Recognizer.SetPropertyNumber("HighConfidenceThreshold", 90); SRprop = objRecoContext.Recognizer.SetPropertyNumber("NormalConfidenceThreshold", 50); SRprop = objRecoContext.Recognizer.SetPropertyNumber("LowConfidenceThreshold", 10); SRprop = objRecoContext.Recognizer.SetPropertyNumber("AdaptationOn", 0); Еще транскрипции с русского на английский! Цитата Russian letter Symbol Pronunciation Я (stressed) ya as ya in yahoo Я (unstressed) ee as ee in meet, but very short Е (stressed) ye as ye in yes Е (unstressed) ee as ee in meet, but very short Ё (always stressed) yo as yo in yonder Ю yoo as the word you И (stressed) ee as ee in meet Russian letter Symbol Pronunciation A (stressed) ah as Ah, but shorter A (unstressed) a as u in but O (stressed) o as aw in law O (unstressed) a as u in but Ы i no English equivalent У oo as oo in wood Э e as e in pet Russian letter Symbol Pronounced as Б (soft) b b in bee Б (hard) b b in but В (soft) v v in view В (hard) v v in voice Г (soft) g g in girl Г (hard) g g in go Д (soft) d d in dew Д (hard) d d in dial З (soft) z z in zeal З (hard) z z in zoom К (soft) k k in okey К (hard) k c in clock Л (soft) l l in leak Л (hard) l l in lump М (soft) m m in muse М (hard) m m in monk Н (soft) n n in need Н (hard) n n in noon П (soft) p p in pew П (hard) p p in mop Р (soft) r no equivalent Р (hard) r no equivalent С (soft) s s in seed, sew С (hard) s s in soup Т (soft) t t in stew Т (hard) t t in ten Ф (soft) f f in few Ф (hard) f f in fault Х (soft) kh h in huge Х (hard) kh h in host Ц (always hard) ts ts in what's up Ч (mostly soft) ch ch in church Ш (hard) sh sh in shield Щ (soft) shch no equivalent й (soft) j y in yes or may |
|
Сообщ.
#85
,
|
|
|
|
Здравствуйте, Roman55555. Появилось ли за год что-нибудь нового по данной теме?
|
|
Сообщ.
#86
,
|
|
|
|
Evgeniyuser, чем вас cmu-sphinx не устраивает как готовое и открытое решение для распознования речи?
p.s. на сколько я вижу roman55555 Unregistered |
|
Сообщ.
#87
,
|
|
|
|
zamir
А если точить под свои нужды? Я понял, что нужно использовать Java? А на С# пойдет? |
|
Сообщ.
#88
,
|
|
|
|
sphinx4 на java
pocketsphinx на Cи - на сколько я понял компилируется и на windows и на linux я про С# ничего не знаю - но если он как-то совместим с Си, то наверное достатоночно подключить библиотеки с Pocketpshinx в C# builder.... |
|
Сообщ.
#89
,
|
|
|
|
zamir
Может подскажете. У меня стоит задача распознать слова (английские и русские) и записать их в определенном порядке в таблицу Excel. Где это проще и лучше будет реализовать? Я начинающий. |
|
Сообщ.
#90
,
|
|
|
|
можно использовать тот-же pocketsphinx
если прямо русские или английские - то надо обобщить все фонемы а языковую модель создать из русских и английских слов можно просто запускать програму и парсить вывод (я так делаю так как на Си не програмирую) а можно написать собственое приложение используя библиотеки pocketsphinx Если нужна помощь, то думаю можно финансово заинтересовать Николая Шмырёва (одного из разработчиков этого продукта) и он вам возможно поможет реализовать задуманное. |
|
Сообщ.
#91
,
|
|
|
|
zamir
Ага, спасибо. Понял. |
|
Сообщ.
#92
,
|
|
|
|
А я мучаю метод Roman55555.Многие слова распознаёт на ура!
Но становится вопрос о транскрипции в его архиве есть "перевод" русских букв на англйские фонемы. Вопрос.Что значат вот эти символы?В xml не знаю в каком порядке должны идти...   - syllable boundary (hyphen) 1 ! Sentence terminator (exclamation mark) 2 & word boundary 3 , Sentence terminator (comma) 4 . Sentence terminator (period) 5 ? Sentence terminator (question mark) 6 _ Silence (underscore) 7 1 Primary stress 8 2 Secondary stress 9 |


|
Сообщ.
#93
,
|
|
|
|
_ вроде как тишина написано
1 первичное ударение 2 вторичное ударение & гранца слова остальное вроде как знаки припенания |
|
Сообщ.
#94
,
|
|
|
|
Спасибо,в принципе как и предпологал.
Но как это правильно использовать в правилах grammar в xml? И зачем знаки припенания,если в правилах настраивается только для одного слова?Или они уже для движка TTS? |
|
Сообщ.
#95
,
|
|
|
|
Не знаю
Я использую sphinx. Вместо XML языковую модель в sphinx указывается в JSGF (по идеи смысловая нагрузка таже самая) вот пример моего файла Цитата #JSGF V1.0; grammar camera; public <camera> = ( <doo1> | <doo2> | <do3> ); <doo1> = <do1> ( <cam1> <prenum> <num1> | <num2> <cam1> ); <doo2> = <do2> ( <cam2> <prenum> <num1> | <num3> <cam2> | <allcam> ); <do1> = ( включить | подключить | выключить | отключить | опросить ); <do2> = ( опросить | опросить состояние | состояние | статус | описание ); <do3> = ( пока | пока пока | досвидание | положить трубку ); <cam1> = ( камеру | видео-камеру ); <cam2> = ( камеры | видео-камеры ); <allcam> = ( всех камер | всех видео-камер | каждой <cam2> ); <prenum> = [ номер ]; <num1> = ( один | два | три | четыре | пять | шесть | семь | восемь | девять ); <num2> = ( первую | вторую | третью | четвёртую | пятую | шестую | седьмую | восьмую | девятую ); <num3> = ( первой | второй | третьей | четвёртой | пятой | шестой | седьмой | восьмой | девятой ); для сравнения JSGF и XML grammar.xml <?xml version="1.0"?> <grammar xmlns="http://www.w3.org/2001/06/grammar" xml:lang="en-US" version="1.0" mode="voice" root="digit"> <rule id="digit"> <one-of> <item>one</item> <item>two</item> <item>three</item> </one-of> </rule> </grammar> grammar.jsgf #JSGF V1.0; grammar digits; public <numbers> = (one | two | three); |
|
Сообщ.
#96
,
|
|
|
|
Ребята, вопрос.
Есть куча надиктованных mp3-файлов и набранные с них тексты. Можно ли их использовать для обучения системы распознаванию? |
|
Сообщ.
#97
,
|
|
|
|
да. я так и делаю.
буду рад, если вы поделитесь своими файлами. |
|
Сообщ.
#98
,
|
|
|
|
я вам в личку мой имейл бросил, можете ответить?
|
|
Сообщ.
#99
,
|
|
|
|
Roman55555 Как работает код на C# c английскими фонемами? Я написал программу по распознаванию русской речи с библиотекой sphinx. Единственная проблема это пополнение базы словаря. Хотелось чтобы можно было делать это автоматом, т.е. имеется слово в единственном или множественном числе, далее создается морфема слова автоматом.
|
0 пользователей читают эту тему (0 гостей и 0 скрытых пользователей)
0 пользователей:
[ Script execution time: 0,1791 ] [ 16 queries used ] [ Generated: 19.04.24, 23:09 GMT ]