

 Генерация размещений
Генерация размещений
|
Наши проекты:
Журнал · Discuz!ML · Wiki · DRKB · Помощь проекту |
||
| ПРАВИЛА | FAQ | Помощь | Поиск | Участники | Календарь | Избранное | RSS |
| [18.118.32.213] |

|
|
Полезные ссылки:
Генерация размещений
|
Сообщ.
#1
,
|
|
|
|
Всем привет!
В стандартной либе (<algorithm>) есть прекрасный механизм работы с перестановками - std::next_permutation. А есть ли что-либо подобное, удобное для работы с размещениями? Допустим, к примеру, я хочу реализовать брутфорс по словарю. И мне нужно из словаря размером D сгенирировать все размещения длинной от M до N, где M>0 и N>=M. |
|
Сообщ.
#2
,
|
|
  |
Что такое сочетания ? И чем не подходит std::next_permutation?
Оно же делает перестановки. А вообще брутфорс по словарю - это когда ты берешь словарь и начинаешь его перебирать, без всяких перестановок. |
|
Сообщ.
#3
,
|
|
|
|
Цитата Wound @ Что такое сочетания ? И чем не подходит std::next_permutation? Тем, что оно делает перестановки.  Цитата Wound @ Оно же делает перестановки. Да. Добавлено Цитата Wound @ А вообще брутфорс по словарю Брутфорс - это подбор путем перебора (без уточнения, как именно перебирается). Словарь может быть из готовых паролей, а может быть из алфавита, с помощью которого методом сочетаний формируются пароли. |
|
Сообщ.
#4
,
|
|
 |
Ты уверен, что тебе нужны именно сочетания, а не размещения?
Сочетания из n элементов по k с использованием next_permutation получаются при помощи создания вектора из (n - k) нулей и k единиц, т.е. вектора длины n. А дальше как-то так:   do { for(int i = 0; i < n; ++i) { // v[i] == 1 означает, что i-ый элемент принадлежит сочетанию } } while(std::next_permutation(v.begin(), v.end()); Если будут нужны размещения, то просто каждое из полученных сочетаний сортируешь и генерируешь все возможные их перестановки. Добавлено Или с размещениями лучше вообще вот так. Генерируешь вектор значений ((n - k) нулей, 1, 2, 3, ... k), и переставляешь уже его. На каждой итерации полагаешь, что если v[i] == 0, то i-ый элемент в размещение не входит, иначе он находится на v[i]-ой позиции. |


|
Сообщ.
#5
,
|
|
|
|
Цитата OpenGL @ Ты уверен, что тебе нужны именно сочетания, а не размещения? Ты прав, порядок важен! Да - нужны размещения! Правлю название темы. Ниже схемка - это так, для памяти  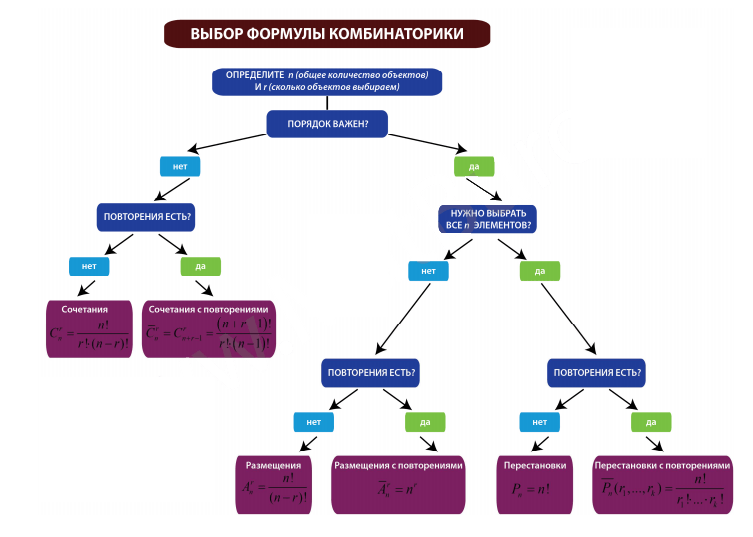 |
|
Сообщ.
#6
,
|
|
 |
На сочетания есть простой рекурсивный алгоритм, размещения из каждого сочетания получаются пермутациями. Не уверен в эффективности, но работает.
|
|
Сообщ.
#7
,
|
|
|
|
Qraizer, есть нюанс ... с повторениями!
Ломает всю картину моего прекрасного мира  |
|
Сообщ.
#8
,
|
|
|
|
У тебя в словаре могут быть повторения?
Добавлено В любом случае повторения легко сводятся к их отсутствию, достаточно лишь добавить к элементам индексы уникальности, учитываемые в сравнениях и игнорируемые в остальных случаях. Т.е. дело лишь за кастомным сравнением и value_type |
|
Сообщ.
#9
,
|
|
|
|
Цитата Qraizer @ У тебя в словаре могут быть повторения? Пусть в словаре, допустим, повторения будут. Но это не должно влиять на решение, т.к. - словарь, это множество уникальных значений, значит дубли из него убираем сразу же перед основным решением. Бытовой пример: Cгенерировать полный вариант набора паролей из алфавита ['a','b'] - длиной, допустим, от 1 до 8. Понятное дело, если "полный" - то с повторениями. "aaaaa" - валидный набор, к примеру. Твое решение? ЗЫ: И тут скорее не сам алгоритм интересен, а именно использование возможностей стандартной библиотеки! Поиск, переборы, перестановки, обмены, срезы ... В общем, всем тем, чем богат #include <algorithm>. |
|
Сообщ.
#10
,
|
|
|
|
Секундочку. Это ж абсолютно другая задача. У тебя не словарь на входе, а набор лексем и правил, как из этого безобразия получить словарь.
|
|
Сообщ.
#11
,
|
|
|
|
Цитата Qraizer @ как из этого безобразия получить словарь Я привел упрощенный вариант - когда в словаре составляющие - символы. Из них строится "Passphrase". Скрытый текст Но словарь может быть и не из символов, а допустим из слов. Это ничего не меняет! "Мама раму мама мама мама мама мыла раму" - валидный вариант. Ну давай на примере, чтобы уже было совсем просто: словарь - 'a','b' длина - три найти все размещения из словаря по длине три? Примеры вразброс: б баб аб бба aaa aa ба ... |
|
Сообщ.
#12
,
|
|
|
|
Та понял я. Просто в контексте "брутфорс по словарю" обычно имеются в виду словарные атаки.
Цитата JoeUser @ У тебя очень простая задача. Считай, что лексемы твоего словаря – это цифры D-ричной системы счисления. Просто перебирай все n-значные числа, где n пробегает весь диапазон от M до N И мне нужно из словаря размером D сгенирировать все размещения длинной от M до N, где M>0 и N>=M. Добавлено Цитата JoeUser @ 2-ичная система, цифры a и b. n пробегает от 1 до 3:словарь - 'a','b' длина - три найти все размещения из словаря по длине три? a b aa ab ba bb aaa aab aba abb baa bab bba bbb Добавлено P.S. Не думаю, что в std что-то существенно сможет помочь. |
|
Сообщ.
#13
,
|
|
|
|
Qraizer,
 |
|
Сообщ.
#14
,
|
|
|
|
Да, что-то я не подумал про то, что тебе не просто размещения, а размещения с повторениями нужны. Их лучше самому написать, приспособить что-то из std вряд-ли будет сильно проще, чем написание. По крайней мере я всегда сам их генерировал.
|
|
Сообщ.
#15
,
|
|
|
|
Цитата Qraizer @ На сочетания есть простой рекурсивный алгоритм, размещения из каждого сочетания получаются пермутациями. Не уверен в эффективности, но работае Правильно делаете, что не уверены в эффективности рекурсии! При решении другой комбинаторной задачи мы выявили, что рекурсия минимум в 3 раза уменьшает скорость работы программы. P.S. В этой связи мы, например, переписали стандартный алгоритм поиска файлов по маске в файловой системе. Убрали рекурсию и сделали все без рекурсии. Эффективностью нового алгоритма не нарадуемся! |
0 пользователей читают эту тему (0 гостей и 0 скрытых пользователей)
0 пользователей:
[ Script execution time: 0,0406 ] [ 16 queries used ] [ Generated: 20.04.24, 00:45 GMT ]